Introduction to Seaborn
Seaborn is a Python data visualization library based on Matplotlib that provides a high-level, aesthetically pleasing interface for creating a wide range of informative and attractive visualizations. Its primary goal is to make it easier for data scientists and analysts to visualize statistical relationships in data. Integrated with Pandas, Seaborn simplifies many visualization tasks and offers a consistent interface that helps users produce charts suitable for both exploratory data analysis and explanatory presentations. Seaborn's customizability and rich set of functions are particularly advantageous when dealing with complex datasets. It brings in several enhancements over Matplotlib, such as improved color palettes, elegant themes, and functions tailored specifically for visualizing statistical relationships.
List of Visualizations Using Seaborn:
Relational Plots:
Categorical Plots:
catplot: A versatile interface for drawing categorical plots.
boxplot: Display the distribution of a categorical variable using boxes and whiskers.
violinplot: Combines aspects of boxplots and KDE plots for categorical data.
stripplot: A scatter plot for categorical variables.
swarmplot: A categorical scatter plot with non-overlapping points.
barplot: Bar charts to represent an estimate of central tendency for a numeric variable.
countplot: Histograms for categorical variables.
Distribution Plots:
histplot: Histograms and binnings for visualizing distributions.
kdeplot: Kernel Density Estimation plots.
ecdfplot: Empirical Cumulative Distribution Functions.
jointplot: Combines multiple plots for bivariate analysis.
pairplot: Plot pairwise relationships in a dataset.
Regression Plots:
Matrix Plots:
Scatter plot
A scatter plot is a type of data visualization that uses dots to represent the values obtained for two different variables - one plotted along the x-axis and the other plotted along the y-axis. Seaborn is a Python data visualization library that provides a high-level interface for creating visually appealing and informative statistical graphics, including scatter plots. Enhancing the visual appeal of plots can help in better understanding and interpretation of data. With Seaborn, adding color and style is straightforward, allowing you to make your plots more engaging. Let's take our scatter plot to the next level by adding more color and style.
# Importing necessary libraries import seaborn as sns import matplotlib.pyplot as plt # Sample data x = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] y = [2, 4, 5, 7, 6, 8, 9, 11, 12, 12] # Setting a style and color palette sns.set_style("whitegrid") # Sets background to white with gray grid lines palette = sns.color_palette("viridis", n_colors=len(x)) # Uses the 'viridis' color palette # Create scatter plot using Seaborn sns.scatterplot(x=x, y=y, palette=palette, size=y, sizes=(50,200), hue=y, legend="full") # Adding title and labels plt.title('Colorful Scatter Plot with Seaborn') plt.xlabel('X Values') plt.ylabel('Y Values') # Display the plot plt.show()# Importing necessary libraries import seaborn as sns import matplotlib.pyplot as plt # Sample data x = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] y = [2, 4, 5, 7, 6, 8, 9, 11, 12, 12] # Setting a style and color palette sns.set_style("whitegrid") # Sets background to white with gray grid lines palette = sns.color_palette("viridis", n_colors=len(x)) # Uses the 'viridis' color palette # Create scatter plot using Seaborn sns.scatterplot(x=x, y=y, palette=palette, size=y, sizes=(50,200), hue=y, legend="full") # Adding title and labels plt.title('Colorful Scatter Plot with Seaborn') plt.xlabel('X Values') plt.ylabel('Y Values') # Display the plot plt.show()# Importing necessary libraries import seaborn as sns import matplotlib.pyplot as plt # Sample data x = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] y = [2, 4, 5, 7, 6, 8, 9, 11, 12, 12] # Setting a style and color palette sns.set_style("whitegrid") # Sets background to white with gray grid lines palette = sns.color_palette("viridis", n_colors=len(x)) # Uses the 'viridis' color palette # Create scatter plot using Seaborn sns.scatterplot(x=x, y=y, palette=palette, size=y, sizes=(50,200), hue=y, legend="full") # Adding title and labels plt.title('Colorful Scatter Plot with Seaborn') plt.xlabel('X Values') plt.ylabel('Y Values') # Display the plot plt.show()

Explanation:
First, we set the background style using sns.set_style(). The "whitegrid" style provides a neat white background with gray grid lines.
We define a color palette. In this case, we're using the "viridis" palette, which provides a range of colors from purple to yellow. We set the number of colors to match the length of our data.
In our sns.scatterplot(), we've made a few enhancements:
palette: This uses the 'viridis' palette we defined.
size: Sizes of the markers are determined by the y values. This means data points with higher y values will have larger markers.
sizes: Defines the range of sizes for the markers.
hue: Colors the markers based on y values. This will give a gradient of colors across our data points.
legend: This displays a legend. "full" means every unique value will get its own entry in the legend.
To create the scatter plot, we use the sns.scatterplot() function. The parameters x and y are used to specify the data for the x and y axes. Just like before, we can customize the color and marker style.
We can use the Matplotlib functions (plt.title(), plt.xlabel(), and plt.ylabel()) to add a title and labels to the x and y axes. Seaborn is built on top of Matplotlib, so they work seamlessly together.
Finally, plt.show() displays the plot.
Seaborn's scatter plot function also comes with additional features like automatic regression line fitting (with sns.regplot()) and grouping data by categories, making it a powerful tool for more advanced visualizations.
Line plots
Line plots are essential for visualizing data points in a sequence or showing trends over an interval. With Seaborn, creating a line plot is straightforward. Let's illustrate this with our data, enhancing the visual appeal just as we did with the scatter plot.
# Importing necessary libraries import seaborn as sns import matplotlib.pyplot as plt # Sample data x = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] y = [2, 4, 5, 7, 6, 8, 9, 11, 12, 12] y2 = [3, 5, 4, 6, 7, 7, 10, 10, 13, 14] # New data set # Setting a style sns.set_style("whitegrid") # Sets background to white with gray grid lines # Create line plot using Seaborn for both y and y2 sns.lineplot(x=x, y=y, label='y', linewidth=2.5) sns.lineplot(x=x, y=y2, label='y2', linewidth=2.5) # Adding title, labels, and legend plt.title('Multiple Lines Plot with Seaborn') plt.xlabel('X Values') plt.ylabel('Y Values') plt.legend() # Display the plot plt.show()# Importing necessary libraries import seaborn as sns import matplotlib.pyplot as plt # Sample data x = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] y = [2, 4, 5, 7, 6, 8, 9, 11, 12, 12] y2 = [3, 5, 4, 6, 7, 7, 10, 10, 13, 14] # New data set # Setting a style sns.set_style("whitegrid") # Sets background to white with gray grid lines # Create line plot using Seaborn for both y and y2 sns.lineplot(x=x, y=y, label='y', linewidth=2.5) sns.lineplot(x=x, y=y2, label='y2', linewidth=2.5) # Adding title, labels, and legend plt.title('Multiple Lines Plot with Seaborn') plt.xlabel('X Values') plt.ylabel('Y Values') plt.legend() # Display the plot plt.show()# Importing necessary libraries import seaborn as sns import matplotlib.pyplot as plt # Sample data x = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] y = [2, 4, 5, 7, 6, 8, 9, 11, 12, 12] y2 = [3, 5, 4, 6, 7, 7, 10, 10, 13, 14] # New data set # Setting a style sns.set_style("whitegrid") # Sets background to white with gray grid lines # Create line plot using Seaborn for both y and y2 sns.lineplot(x=x, y=y, label='y', linewidth=2.5) sns.lineplot(x=x, y=y2, label='y2', linewidth=2.5) # Adding title, labels, and legend plt.title('Multiple Lines Plot with Seaborn') plt.xlabel('X Values') plt.ylabel('Y Values') plt.legend() # Display the plot plt.show()

Explanation
To plot multiple lines, we simply make multiple calls to sns.lineplot(). Each call will overlay a new line on the plot.
The label parameter is used to provide a name for each line, which will be displayed in the legend.
The plt.legend() function is used to display a legend, showing the labels for each line.
With this approach, both lines are clearly visible, and using the legend, it's easy to differentiate between the two datasets.
catplot
Seaborn's catplot is a function that provides access to several axes-level functions that show the relationship between a numerical and one or more categorical variables using one of several visual representations. The kind of plot to produce is specified with the kind parameter:
"point" : point plot
"bar" : bar plot
"strip" : strip plot
"swarm" : swarm plot
"box" : box plot
"violin" : violin plot
"boxen" : boxen plot
The catplot function provides a higher-level interface that is built on top of other Seaborn functions, and it's particularly useful when you want to visualize different types/categories in your dataset.
# Importing necessary libraries import seaborn as sns import matplotlib.pyplot as plt import pandas as pd # Added this for DataFrame conversion # Sample data data_dict = { 'Category': ['A', 'B', 'A', 'A', 'B', 'B', 'A', 'A', 'B', 'B'], 'Price': [15, 25, 14, 35, 45, 35, 25, 55, 50, 60] } # Convert dictionary to DataFrame data = pd.DataFrame(data_dict) # Create catplot using Seaborn sns.catplot(x='Category', y='Price', data=data, kind='bar') # Adding title plt.title('Bar Catplot with Seaborn') # Display the plot plt.show()# Importing necessary libraries import seaborn as sns import matplotlib.pyplot as plt import pandas as pd # Added this for DataFrame conversion # Sample data data_dict = { 'Category': ['A', 'B', 'A', 'A', 'B', 'B', 'A', 'A', 'B', 'B'], 'Price': [15, 25, 14, 35, 45, 35, 25, 55, 50, 60] } # Convert dictionary to DataFrame data = pd.DataFrame(data_dict) # Create catplot using Seaborn sns.catplot(x='Category', y='Price', data=data, kind='bar') # Adding title plt.title('Bar Catplot with Seaborn') # Display the plot plt.show()# Importing necessary libraries import seaborn as sns import matplotlib.pyplot as plt import pandas as pd # Added this for DataFrame conversion # Sample data data_dict = { 'Category': ['A', 'B', 'A', 'A', 'B', 'B', 'A', 'A', 'B', 'B'], 'Price': [15, 25, 14, 35, 45, 35, 25, 55, 50, 60] } # Convert dictionary to DataFrame data = pd.DataFrame(data_dict) # Create catplot using Seaborn sns.catplot(x='Category', y='Price', data=data, kind='bar') # Adding title plt.title('Bar Catplot with Seaborn') # Display the plot plt.show()

Explanation
We start by importing the necessary libraries. Here, we need Seaborn for the catplot and Matplotlib's pyplot module for additional customization.
We define a simple dataset data with categories 'A' and 'B', and their respective prices.
We use sns.catplot() to visualize this data:
x specifies the categorical variable.
y specifies the numerical variable.
data specifies the dataset.
kind specifies the type of plot. In this case, we've used a bar plot.
We add a title using plt.title().
Finally, plt.show() displays the plot.
In the resulting plot, the categories (A and B) are displayed on the x-axis, and their average prices are displayed on the y-axis, represented as bars. The height of the bars indicates the average price for each category. This visualization provides a clear comparison between the average prices of the two categories.
Box Plot
Box Plots, also known as whisker plots, are used to display the distribution of data based on a five-number summary: the minimum, the first quartile (Q1), the median, the third quartile (Q3), and the maximum. They are particularly useful to quickly visualize where the majority of the values lie in a dataset and to identify potential outliers.
Using Seaborn's catplot function with the kind parameter set to "box", we can easily create boxplots. Let's use the same sample data to produce a boxplot.
# Importing necessary libraries import seaborn as sns import matplotlib.pyplot as plt import pandas as pd # For DataFrame conversion # Sample data data_dict = { 'Category': ['A', 'B', 'A', 'A', 'B', 'B', 'A', 'A', 'B', 'B'], 'Price': [15, 25, 14, 35, 45, 35, 25, 55, 50, 60] } # Convert dictionary to DataFrame data = pd.DataFrame(data_dict) # Create catplot using Seaborn with kind='box' sns.catplot(x='Category', y='Price', data=data, kind='box') # Adding title plt.title('Boxplot with Seaborn') # Display the plot plt.show()# Importing necessary libraries import seaborn as sns import matplotlib.pyplot as plt import pandas as pd # For DataFrame conversion # Sample data data_dict = { 'Category': ['A', 'B', 'A', 'A', 'B', 'B', 'A', 'A', 'B', 'B'], 'Price': [15, 25, 14, 35, 45, 35, 25, 55, 50, 60] } # Convert dictionary to DataFrame data = pd.DataFrame(data_dict) # Create catplot using Seaborn with kind='box' sns.catplot(x='Category', y='Price', data=data, kind='box') # Adding title plt.title('Boxplot with Seaborn') # Display the plot plt.show()# Importing necessary libraries import seaborn as sns import matplotlib.pyplot as plt import pandas as pd # For DataFrame conversion # Sample data data_dict = { 'Category': ['A', 'B', 'A', 'A', 'B', 'B', 'A', 'A', 'B', 'B'], 'Price': [15, 25, 14, 35, 45, 35, 25, 55, 50, 60] } # Convert dictionary to DataFrame data = pd.DataFrame(data_dict) # Create catplot using Seaborn with kind='box' sns.catplot(x='Category', y='Price', data=data, kind='box') # Adding title plt.title('Boxplot with Seaborn') # Display the plot plt.show()
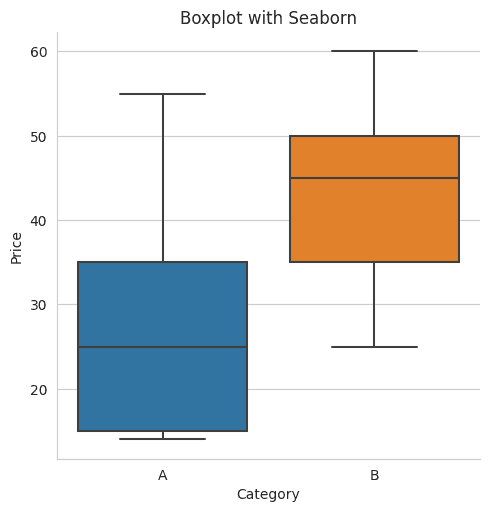
Explanation
After importing necessary libraries and creating our dataset, we use sns.catplot() to create a boxplot:
x specifies the categorical variable.
y specifies the numerical variable.
data specifies the dataset.
kind is set to 'box' to create a boxplot.
A box in the boxplot represents the IQR (Interquartile Range) between the first and third quartiles (the box edges). The line inside the box represents the median. The "whiskers" (lines that extend out from the box) indicate the range for the majority of the data, while points outside the whiskers can be considered as potential outliers.
Finally, we add a title and display the plot.
Using this boxplot, you can quickly get insights into the distribution of prices for each category.
Violin plot
The violin plot is a method of plotting numeric data and can be understood as a combination of a boxplot and a density plot. It provides a visualization of the distribution of the data, its probability density, and its cumulative distribution. The width of the violin at different values indicates the density of the data at that value, with wider sections representing higher density (more data points).
Seaborn makes it easy to create violin plots through its violinplot function. Let's use the same sample data to produce a violin plot.
# Importing necessary libraries import seaborn as sns import matplotlib.pyplot as plt import pandas as pd # For DataFrame conversion # Sample data data_dict = { 'Category': ['A', 'B', 'A', 'A', 'B', 'B', 'A', 'A', 'B', 'B'], 'Price': [15, 25, 14, 35, 45, 35, 25, 55, 50, 60] } # Convert dictionary to DataFrame data = pd.DataFrame(data_dict) # Create violin plot using Seaborn sns.violinplot(x='Category', y='Price', data=data, inner='quartile') # Adding title plt.title('Violin Plot with Seaborn') # Display the plot plt.show()# Importing necessary libraries import seaborn as sns import matplotlib.pyplot as plt import pandas as pd # For DataFrame conversion # Sample data data_dict = { 'Category': ['A', 'B', 'A', 'A', 'B', 'B', 'A', 'A', 'B', 'B'], 'Price': [15, 25, 14, 35, 45, 35, 25, 55, 50, 60] } # Convert dictionary to DataFrame data = pd.DataFrame(data_dict) # Create violin plot using Seaborn sns.violinplot(x='Category', y='Price', data=data, inner='quartile') # Adding title plt.title('Violin Plot with Seaborn') # Display the plot plt.show()# Importing necessary libraries import seaborn as sns import matplotlib.pyplot as plt import pandas as pd # For DataFrame conversion # Sample data data_dict = { 'Category': ['A', 'B', 'A', 'A', 'B', 'B', 'A', 'A', 'B', 'B'], 'Price': [15, 25, 14, 35, 45, 35, 25, 55, 50, 60] } # Convert dictionary to DataFrame data = pd.DataFrame(data_dict) # Create violin plot using Seaborn sns.violinplot(x='Category', y='Price', data=data, inner='quartile') # Adding title plt.title('Violin Plot with Seaborn') # Display the plot plt.show()
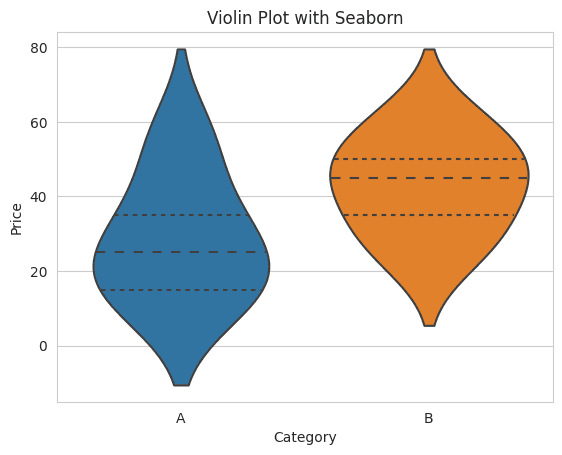
Explanation
After setting up our libraries and data, we use sns.violinplot() to produce the violin plot.
x specifies the categorical variable.
y specifies the numerical variable.
data specifies the dataset.
inner is set to 'quartile' to display the quartile lines inside the violin. Other options for inner include 'box', 'stick', and 'point'.
The violin plot has two main components: the outer shape, representing the kernel density estimation, and the inner part, which, in our case, shows the quartiles.
The width of the violin at different values indicates the data's density.
The broader sections of the violin represent areas where data points are denser, while the narrower sections represent areas with fewer data points.
Finally, we add a title and display the plot.
By using a violin plot, you can visually grasp the data distribution and density for each category more comprehensively than with a box plot alone.
Strip plot
Strip plots, also known as categorical scatter plots, offer a detailed view of data distribution. They plot individual data points for each category, allowing viewers to discern nuances in data density and distribution. Particularly when working with datasets that feature multiple categories and a sizable number of points, applying color can help distinguish between these categories more effectively. The sns.stripplot() function in Seaborn facilitates this visualization.
To enhance the clarity and visual appeal of strip plots, especially with larger and more diverse datasets, color can play a crucial role. Colors can not only help in distinguishing between categories but also make the visualization more engaging.
# Importing necessary libraries import seaborn as sns import matplotlib.pyplot as plt import pandas as pd # For DataFrame conversion # Sample data with more categories and values data_dict = { 'Category': ['A', 'B', 'C', 'A', 'B', 'C', 'A', 'B', 'C', 'A', 'A', 'B', 'B', 'C', 'C', 'A', 'B', 'C'], 'Price': [15, 20, 18, 25, 30, 22, 14, 32, 28, 35, 34, 26, 27, 24, 29, 37, 33, 36] } # Convert dictionary to DataFrame data = pd.DataFrame(data_dict) # Create strip plot using Seaborn palette = sns.color_palette("viridis", n_colors=len(data['Category'].unique())) # Defining a color palette sns.stripplot(x='Category', y='Price', data=data, jitter=True, marker='o', alpha=0.7, palette=palette) # Adding title plt.title('Colorful Strip Plot with Seaborn') # Display the plot plt.show()# Importing necessary libraries import seaborn as sns import matplotlib.pyplot as plt import pandas as pd # For DataFrame conversion # Sample data with more categories and values data_dict = { 'Category': ['A', 'B', 'C', 'A', 'B', 'C', 'A', 'B', 'C', 'A', 'A', 'B', 'B', 'C', 'C', 'A', 'B', 'C'], 'Price': [15, 20, 18, 25, 30, 22, 14, 32, 28, 35, 34, 26, 27, 24, 29, 37, 33, 36] } # Convert dictionary to DataFrame data = pd.DataFrame(data_dict) # Create strip plot using Seaborn palette = sns.color_palette("viridis", n_colors=len(data['Category'].unique())) # Defining a color palette sns.stripplot(x='Category', y='Price', data=data, jitter=True, marker='o', alpha=0.7, palette=palette) # Adding title plt.title('Colorful Strip Plot with Seaborn') # Display the plot plt.show()# Importing necessary libraries import seaborn as sns import matplotlib.pyplot as plt import pandas as pd # For DataFrame conversion # Sample data with more categories and values data_dict = { 'Category': ['A', 'B', 'C', 'A', 'B', 'C', 'A', 'B', 'C', 'A', 'A', 'B', 'B', 'C', 'C', 'A', 'B', 'C'], 'Price': [15, 20, 18, 25, 30, 22, 14, 32, 28, 35, 34, 26, 27, 24, 29, 37, 33, 36] } # Convert dictionary to DataFrame data = pd.DataFrame(data_dict) # Create strip plot using Seaborn palette = sns.color_palette("viridis", n_colors=len(data['Category'].unique())) # Defining a color palette sns.stripplot(x='Category', y='Price', data=data, jitter=True, marker='o', alpha=0.7, palette=palette) # Adding title plt.title('Colorful Strip Plot with Seaborn') # Display the plot plt.show()
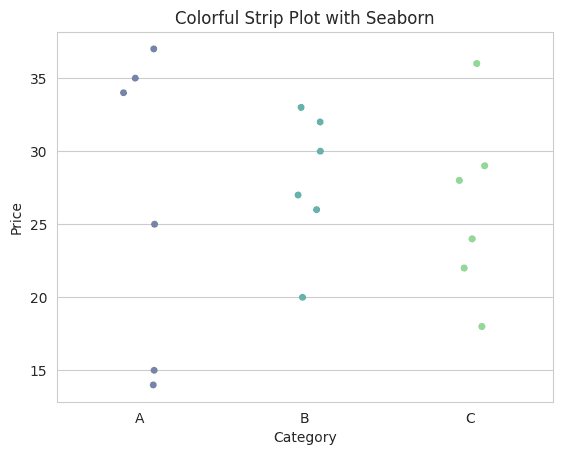
Explanation
Setting up Data and Libraries: After importing the necessary libraries, we expand our dataset to include more categories and data points.
Visualization using sns.stripplot():
x and y represent the categorical and numerical variables respectively.
data indicates the dataset.
The jitter parameter, set to True, introduces a slight randomness to the horizontal placement of data points. This helps in preventing overlap and makes the distribution more readable.
marker determines the marker style, and alpha manages the transparency of the markers.
palette is used to specify the colors for each category. We use Seaborn's color_palette function to generate a color palette, ensuring each category gets a distinct color.
Enhancing Readability with Color: By applying a color palette, we've ensured each category gets assigned a distinct color, making them easily distinguishable.
Presentation: We add a title for context and use plt.show() to render the visualization.
The colorful strip plot allows for a clearer differentiation between categories, providing both depth and visual appeal.
Swarmplot
The swarmplot is another categorical plot type in Seaborn. It's similar to a strip plot but positions each scatter point (representing a data point) on the categorical axis with minimal overlap, ensuring that each data point is visible. This positioning is achieved by using an algorithm that prevents data points from overlapping. The result looks somewhat like a "swarm" of points, hence the name.
A swarmplot provides a good balance between a strip plot (where dots can overlap and make the distribution hard to interpret) and a violin or box plot (which provide summarized views of distributions). It gives a clear view of all individual data points without any overlap while also providing a sense of the distribution.
# Importing necessary libraries import seaborn as sns import matplotlib.pyplot as plt import pandas as pd import numpy as np # For random data generation # Generating larger dataset np.random.seed(0) # Setting seed for reproducibility categories = ['A', 'B', 'C', 'D', 'E'] n_points = 1000 data_dict = { 'Category': np.random.choice(categories, n_points), 'Price': np.random.rand(n_points) * 100 # Prices between 0 and 100 } # Convert dictionary to DataFrame data = pd.DataFrame(data_dict) # Create swarm plot using Seaborn palette = sns.color_palette("viridis", n_colors=len(categories)) sns.swarmplot(x='Category', y='Price', data=data, palette=palette, size=5) # Adding title and labels plt.title('Swarm Plot with Seaborn for Large Dataset') plt.xlabel('Product Category') plt.ylabel('Price ($)') # Display the plot plt.tight_layout() # Adjusts the plot dimensions for better display plt.show() # Importing necessary libraries import seaborn as sns import matplotlib.pyplot as plt import pandas as pd import numpy as np # For random data generation # Generating larger dataset np.random.seed(0) # Setting seed for reproducibility categories = ['A', 'B', 'C', 'D', 'E'] n_points = 1000 data_dict = { 'Category': np.random.choice(categories, n_points), 'Price': np.random.rand(n_points) * 100 # Prices between 0 and 100 } # Convert dictionary to DataFrame data = pd.DataFrame(data_dict) # Create swarm plot using Seaborn palette = sns.color_palette("viridis", n_colors=len(categories)) sns.swarmplot(x='Category', y='Price', data=data, palette=palette, size=5) # Adding title and labels plt.title('Swarm Plot with Seaborn for Large Dataset') plt.xlabel('Product Category') plt.ylabel('Price ($)') # Display the plot plt.tight_layout() # Adjusts the plot dimensions for better display plt.show() # Importing necessary libraries import seaborn as sns import matplotlib.pyplot as plt import pandas as pd import numpy as np # For random data generation # Generating larger dataset np.random.seed(0) # Setting seed for reproducibility categories = ['A', 'B', 'C', 'D', 'E'] n_points = 1000 data_dict = { 'Category': np.random.choice(categories, n_points), 'Price': np.random.rand(n_points) * 100 # Prices between 0 and 100 } # Convert dictionary to DataFrame data = pd.DataFrame(data_dict) # Create swarm plot using Seaborn palette = sns.color_palette("viridis", n_colors=len(categories)) sns.swarmplot(x='Category', y='Price', data=data, palette=palette, size=5) # Adding title and labels plt.title('Swarm Plot with Seaborn for Large Dataset') plt.xlabel('Product Category') plt.ylabel('Price ($)') # Display the plot plt.tight_layout() # Adjusts the plot dimensions for better display plt.show()Explanation
Generating a Larger Dataset: We use numpy to generate a random dataset with 1000 points. The data consists of random categories (from A to E) and prices (between 0 and 100).
Visualization with sns.swarmplot():
We specify x and y as the categorical and numerical variables, respectively.
Our dataset is passed to the data argument.
We define a color palette and assign it to the palette argument.
The size argument adjusts the size of the markers in the plot for better visualization.
Title and Labels: We add a title, x-label, and y-label for better clarity and understanding of the visualization.
Displaying the Plot: plt.tight_layout() is used to adjust the plot's dimensions for better visualization. Then, we use plt.show() to display the plot.
The resulting swarmplot shows the distribution of data points for each category, ensuring no overlap, providing a clear view of individual data points and the overall distribution.
Barplot
A barplot is a common visual tool for displaying and comparing the quantities of different categories. In Seaborn, the barplot function is used to achieve this, plotting the mean (or other estimator) of a numerical variable for each category in a categorical variable. It also automatically computes a confidence interval around the estimate and draws it using error bars.
Using barplots, we can compare the average (or other statistic) of a numerical variable across different categories. This can be useful for visualizing and comparing metrics across different groups.
Let's illustrate this with an example
# Importing necessary libraries import seaborn as sns import matplotlib.pyplot as plt import pandas as pd import numpy as np # For random data generation # Generating larger dataset np.random.seed(42) # Setting seed for reproducibility categories = ['A', 'B', 'C', 'D', 'E'] n_points = 1000 data_dict = { 'Category': np.random.choice(categories, n_points), 'Value': np.random.rand(n_points) * 100 # Random values between 0 and 100 } # Convert dictionary to DataFrame data = pd.DataFrame(data_dict) # Create bar plot using Seaborn palette = sns.color_palette("viridis", n_colors=len(categories)) sns.barplot(x='Category', y='Value', data=data, palette=palette, ci='sd') # Plotting with standard deviation as the error bar # Adding title and labels plt.title('Bar Plot with Seaborn') plt.xlabel('Category') plt.ylabel('Average Value') # Display the plot plt.tight_layout() # Adjusts the plot dimensions for better display plt.show()# Importing necessary libraries import seaborn as sns import matplotlib.pyplot as plt import pandas as pd import numpy as np # For random data generation # Generating larger dataset np.random.seed(42) # Setting seed for reproducibility categories = ['A', 'B', 'C', 'D', 'E'] n_points = 1000 data_dict = { 'Category': np.random.choice(categories, n_points), 'Value': np.random.rand(n_points) * 100 # Random values between 0 and 100 } # Convert dictionary to DataFrame data = pd.DataFrame(data_dict) # Create bar plot using Seaborn palette = sns.color_palette("viridis", n_colors=len(categories)) sns.barplot(x='Category', y='Value', data=data, palette=palette, ci='sd') # Plotting with standard deviation as the error bar # Adding title and labels plt.title('Bar Plot with Seaborn') plt.xlabel('Category') plt.ylabel('Average Value') # Display the plot plt.tight_layout() # Adjusts the plot dimensions for better display plt.show()# Importing necessary libraries import seaborn as sns import matplotlib.pyplot as plt import pandas as pd import numpy as np # For random data generation # Generating larger dataset np.random.seed(42) # Setting seed for reproducibility categories = ['A', 'B', 'C', 'D', 'E'] n_points = 1000 data_dict = { 'Category': np.random.choice(categories, n_points), 'Value': np.random.rand(n_points) * 100 # Random values between 0 and 100 } # Convert dictionary to DataFrame data = pd.DataFrame(data_dict) # Create bar plot using Seaborn palette = sns.color_palette("viridis", n_colors=len(categories)) sns.barplot(x='Category', y='Value', data=data, palette=palette, ci='sd') # Plotting with standard deviation as the error bar # Adding title and labels plt.title('Bar Plot with Seaborn') plt.xlabel('Category') plt.ylabel('Average Value') # Display the plot plt.tight_layout() # Adjusts the plot dimensions for better display plt.show()

Explanation
Generating a Larger Dataset: We create a dataset with 1000 random data points, assigning them to random categories and giving them random values.
Visualization with sns.barplot():
x and y represent the categorical and numerical variables, respectively.
The data argument is provided with our dataset.
We set a color palette with the palette argument.
The ci argument determines the computation for the error bars. Here, we use the standard deviation ('sd'), but it can also compute a confidence interval for the mean if desired.
Title and Labels: For clarity, we add a title, x-label, and y-label.
Displaying the Plot: We use plt.tight_layout() to ensure the plot is displayed cleanly, especially with larger datasets, and then plt.show() to render the plot.
With this barplot, you can visualize the average value (or other statistics) of the Value variable for each category, along with the variation in the form of error bars.
Countplot
A countplot is a type of bar plot where the height of each bar represents the number of data points in each category. It is useful for visualizing the counts of categorical data. In Seaborn, the countplot function is designed specifically for this purpose. Essentially, a countplot is a histogram across a categorical variable, as opposed to a numerical one.
Let's illustrate the use of countplot with a larger dataset, showcasing how many data points exist for each category.
# Importing necessary libraries import seaborn as sns import matplotlib.pyplot as plt import pandas as pd import numpy as np # For random data generation # Generating larger dataset np.random.seed(10) # Setting seed for reproducibility categories = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H'] n_points = 2000 data_dict = { 'Category': np.random.choice(categories, n_points, p=[0.1, 0.15, 0.2, 0.15, 0.1, 0.1, 0.1, 0.1]) } # Convert dictionary to DataFrame data = pd.DataFrame(data_dict) # Using Seaborn's countplot function to visualize the counts of each category palette = sns.color_palette("viridis", n_colors=len(categories)) sns.countplot(x='Category', data=data, palette=palette, order=sorted(data['Category'].unique())) # Adding title and labels plt.title('Count Plot with Seaborn for Large Dataset') plt.xlabel('Category') plt.ylabel('Count') # Display the plot plt.tight_layout() # Adjusts the plot dimensions for better display plt.show() # Importing necessary libraries import seaborn as sns import matplotlib.pyplot as plt import pandas as pd import numpy as np # For random data generation # Generating larger dataset np.random.seed(10) # Setting seed for reproducibility categories = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H'] n_points = 2000 data_dict = { 'Category': np.random.choice(categories, n_points, p=[0.1, 0.15, 0.2, 0.15, 0.1, 0.1, 0.1, 0.1]) } # Convert dictionary to DataFrame data = pd.DataFrame(data_dict) # Using Seaborn's countplot function to visualize the counts of each category palette = sns.color_palette("viridis", n_colors=len(categories)) sns.countplot(x='Category', data=data, palette=palette, order=sorted(data['Category'].unique())) # Adding title and labels plt.title('Count Plot with Seaborn for Large Dataset') plt.xlabel('Category') plt.ylabel('Count') # Display the plot plt.tight_layout() # Adjusts the plot dimensions for better display plt.show() # Importing necessary libraries import seaborn as sns import matplotlib.pyplot as plt import pandas as pd import numpy as np # For random data generation # Generating larger dataset np.random.seed(10) # Setting seed for reproducibility categories = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H'] n_points = 2000 data_dict = { 'Category': np.random.choice(categories, n_points, p=[0.1, 0.15, 0.2, 0.15, 0.1, 0.1, 0.1, 0.1]) } # Convert dictionary to DataFrame data = pd.DataFrame(data_dict) # Using Seaborn's countplot function to visualize the counts of each category palette = sns.color_palette("viridis", n_colors=len(categories)) sns.countplot(x='Category', data=data, palette=palette, order=sorted(data['Category'].unique())) # Adding title and labels plt.title('Count Plot with Seaborn for Large Dataset') plt.xlabel('Category') plt.ylabel('Count') # Display the plot plt.tight_layout() # Adjusts the plot dimensions for better display plt.show()

Explanation
Generating a Larger Dataset: We use np.random.choice to generate a dataset of 2000 data points randomly assigned to one of the categories. We also provide a probability distribution with the p parameter to show that categories can have varying counts.
Visualization with sns.countplot():
x represents the categorical variable.
The dataset is passed to the data argument.
We use a color palette (here, "viridis") to assign distinct colors to each category.
The order parameter is used to display the bars in sorted order.
Title and Labels: A title is added for clarity, along with x and y labels to describe the axes.
Displaying the Plot: The plt.tight_layout() function is used to adjust the plot dimensions for better display, and plt.show() renders the plot.
The resulting countplot clearly displays the number of occurrences for each category, giving a visual representation of the distribution of our categorical data.
Distribution Plots:
Histplot
A histplot in Seaborn is a tool used to represent the distribution of numerical data in the form of a histogram. A histogram divides the continuous data into intervals (or "bins") and counts the number of observations that fall into each bin. The histplot function in Seaborn provides flexibility to visualize data distributions with options for both histograms and kernel density estimation.
Let's illustrate the use of histplot with a larger dataset.
# Importing necessary libraries import seaborn as sns import matplotlib.pyplot as plt import numpy as np # For random data generation # Generating larger dataset np.random.seed(15) # Setting seed for reproducibility # Generating 5000 data points from a normal distribution values = np.random.randn(5000) # Using Seaborn's histplot function to visualize the data distribution palette = sns.color_palette("viridis", n_colors=2) sns.histplot(values, bins=50, kde=True, color=palette[0], line_kws={"color": palette[1], "linewidth": 2}) # Adding title and labels plt.title('Histogram with Seaborn') plt.xlabel('Value') plt.ylabel('Count') # Display the plot plt.tight_layout() # Adjusts the plot dimensions for better display plt.show() # Importing necessary libraries import seaborn as sns import matplotlib.pyplot as plt import numpy as np # For random data generation # Generating larger dataset np.random.seed(15) # Setting seed for reproducibility # Generating 5000 data points from a normal distribution values = np.random.randn(5000) # Using Seaborn's histplot function to visualize the data distribution palette = sns.color_palette("viridis", n_colors=2) sns.histplot(values, bins=50, kde=True, color=palette[0], line_kws={"color": palette[1], "linewidth": 2}) # Adding title and labels plt.title('Histogram with Seaborn') plt.xlabel('Value') plt.ylabel('Count') # Display the plot plt.tight_layout() # Adjusts the plot dimensions for better display plt.show() # Importing necessary libraries import seaborn as sns import matplotlib.pyplot as plt import numpy as np # For random data generation # Generating larger dataset np.random.seed(15) # Setting seed for reproducibility # Generating 5000 data points from a normal distribution values = np.random.randn(5000) # Using Seaborn's histplot function to visualize the data distribution palette = sns.color_palette("viridis", n_colors=2) sns.histplot(values, bins=50, kde=True, color=palette[0], line_kws={"color": palette[1], "linewidth": 2}) # Adding title and labels plt.title('Histogram with Seaborn') plt.xlabel('Value') plt.ylabel('Count') # Display the plot plt.tight_layout() # Adjusts the plot dimensions for better display plt.show()
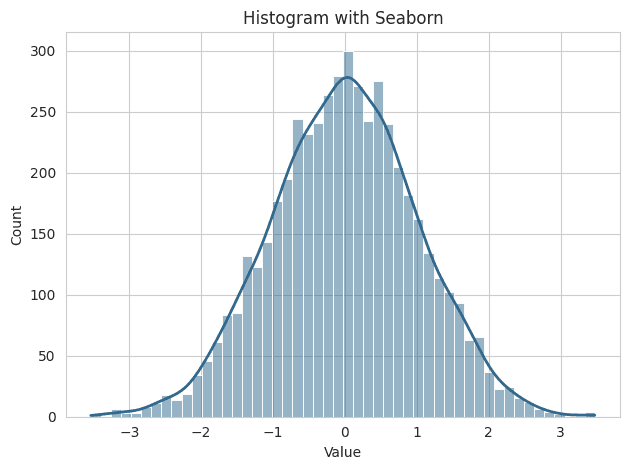
Explanation
Data Generation:
Visualization with sns.histplot():
bins=50 divides the data into 50 intervals.
kde=True overlays a Kernel Density Estimation (KDE) on the histogram.
Colors for the histogram and KDE are fetched from the "viridis" palette.
Labels and Title:
Display:
In essence, this code visualizes the distribution of 5000 data points using a histogram and overlays it with a KDE curve for a smooth representation. This plot shows the bell shape distribution of the data.
Kernel Density Estimation
KDE (Kernel Density Estimation) is used for visualizing the probability density of a continuous variable. It provides a smoothed version of the histogram and is particularly helpful when you want to visualize how the underlying data distribution looks without the jaggedness or interruptions of a histogram.
# Importing necessary libraries import seaborn as sns import matplotlib.pyplot as plt import numpy as np # Generating dataset np.random.seed(42) data = np.random.randn(1000) # Using Seaborn's kdeplot function to visualize the data distribution palette = sns.color_palette("viridis", n_colors=2) sns.kdeplot(data, color=palette[0], shade=True, linewidth=2) # Adding title and labels plt.title('Kernel Density Estimation with Seaborn') plt.xlabel('Value') plt.ylabel('Density') # Display the plot plt.tight_layout() plt.show() # Importing necessary libraries import seaborn as sns import matplotlib.pyplot as plt import numpy as np # Generating dataset np.random.seed(42) data = np.random.randn(1000) # Using Seaborn's kdeplot function to visualize the data distribution palette = sns.color_palette("viridis", n_colors=2) sns.kdeplot(data, color=palette[0], shade=True, linewidth=2) # Adding title and labels plt.title('Kernel Density Estimation with Seaborn') plt.xlabel('Value') plt.ylabel('Density') # Display the plot plt.tight_layout() plt.show() # Importing necessary libraries import seaborn as sns import matplotlib.pyplot as plt import numpy as np # Generating dataset np.random.seed(42) data = np.random.randn(1000) # Using Seaborn's kdeplot function to visualize the data distribution palette = sns.color_palette("viridis", n_colors=2) sns.kdeplot(data, color=palette[0], shade=True, linewidth=2) # Adding title and labels plt.title('Kernel Density Estimation with Seaborn') plt.xlabel('Value') plt.ylabel('Density') # Display the plot plt.tight_layout() plt.show()

Explanation:
Data Generation:
Visualization with sns.kdeplot():
The primary data is passed as the first argument.
color=palette[0] sets the line color.
shade=True fills the area under the KDE curve.
linewidth=2 sets the width of the KDE line.
Labels and Title:
Display:
The resulting plot provides a smoothed visualization of the data distribution, highlighting the density of data at various points. This plot shows bell-shape distribution of the data.
Empirical cumulative distribution function plot
The ecdfplot function in Seaborn provides a way to visualize the empirical cumulative distribution function (ECDF) of a dataset. ECDF represents the proportion or count of observations falling below each unique value in a dataset. Compared to a histogram or a KDE, an ECDF has the advantage that each observation is visualized directly, meaning there are no binning or smoothing parameters that need to be adjusted. It also aids direct comparisons between multiple distributions.
# Importing necessary libraries import seaborn as sns import matplotlib.pyplot as plt import numpy as np # Generating dataset np.random.seed(42) data = np.random.randn(1000) # Using Seaborn's ecdfplot function to visualize the empirical cumulative distribution palette = sns.color_palette("viridis", n_colors=2) sns.ecdfplot(data, color=palette[0], linewidth=2) # Adding title and labels plt.title('ECDF Plot with Seaborn') plt.xlabel('Value') plt.ylabel('Proportion of Data') # Display the plot plt.tight_layout() plt.show() # Importing necessary libraries import seaborn as sns import matplotlib.pyplot as plt import numpy as np # Generating dataset np.random.seed(42) data = np.random.randn(1000) # Using Seaborn's ecdfplot function to visualize the empirical cumulative distribution palette = sns.color_palette("viridis", n_colors=2) sns.ecdfplot(data, color=palette[0], linewidth=2) # Adding title and labels plt.title('ECDF Plot with Seaborn') plt.xlabel('Value') plt.ylabel('Proportion of Data') # Display the plot plt.tight_layout() plt.show() # Importing necessary libraries import seaborn as sns import matplotlib.pyplot as plt import numpy as np # Generating dataset np.random.seed(42) data = np.random.randn(1000) # Using Seaborn's ecdfplot function to visualize the empirical cumulative distribution palette = sns.color_palette("viridis", n_colors=2) sns.ecdfplot(data, color=palette[0], linewidth=2) # Adding title and labels plt.title('ECDF Plot with Seaborn') plt.xlabel('Value') plt.ylabel('Proportion of Data') # Display the plot plt.tight_layout() plt.show()
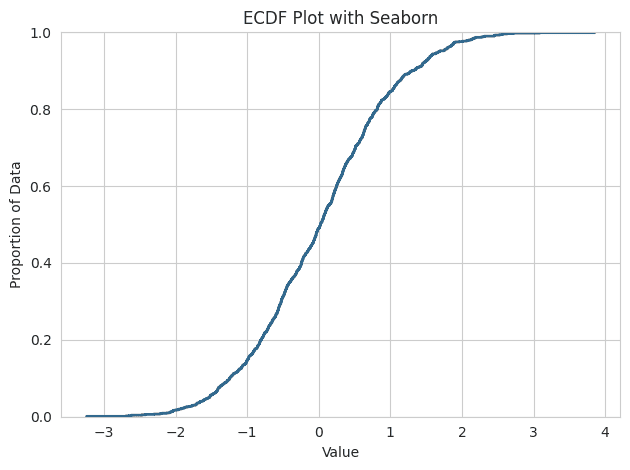
Explanation:
Data Generation:
Visualization with sns.ecdfplot():
The dataset data is passed as the primary argument.
color=palette[0] sets the line color for the ECDF.
linewidth=2 sets the width of the ECDF line.
Labels and Title:
Display:
The ECDF plot provides a way to visualize all the data points in their respective percentiles, allowing you to quickly assess the distribution and proportions of your dataset. ECDF plot suggests that the dataset is somewhat symmetric and possibly close to a normal distribution, with the bulk of the data values falling between -2 and 2. There doesn't appear to be any significant outliers present.
Jointplot
A jointplot is a combination of scatter plot and histogram that helps in visualizing the bivariate distribution of two variables along with their univariate distribution. It provides a way to understand both the individual distributions of the variables and their mutual relationship in one glance.
import numpy as np import seaborn as sns import matplotlib.pyplot as plt # Generating synthetic data np.random.seed(42) x = np.random.randn(150) y = 2 * x + np.random.randn(150) # Creating the jointplot sns.jointplot(x=x, y=y, kind='scatter', color='m') plt.show()
import numpy as np import seaborn as sns import matplotlib.pyplot as plt # Generating synthetic data np.random.seed(42) x = np.random.randn(150) y = 2 * x + np.random.randn(150) # Creating the jointplot sns.jointplot(x=x, y=y, kind='scatter', color='m') plt.show()
import numpy as np import seaborn as sns import matplotlib.pyplot as plt # Generating synthetic data np.random.seed(42) x = np.random.randn(150) y = 2 * x + np.random.randn(150) # Creating the jointplot sns.jointplot(x=x, y=y, kind='scatter', color='m') plt.show()
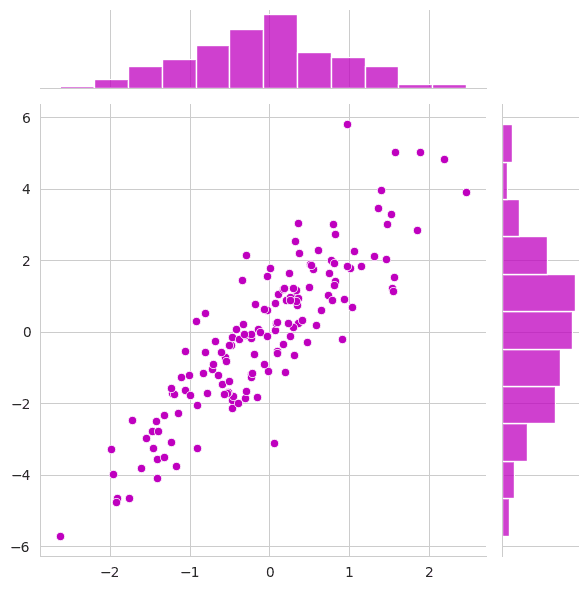
Explanation: In the above code:
We first generate some synthetic data, with y values being roughly twice the x values, with some added noise.
We then use the jointplot function from Seaborn to create a scatter plot for the data. The parameter kind defines the kind of plot to draw on the joint axis. Setting it to 'scatter' results in a scatter plot, but it can also be set to other types like 'hex', 'kde', etc.
The histograms on the top and right side of the joint plot show the univariate distributions of x and y variables respectively. This allows us to see not only how x and y relate to each other but also their individual distributions.
The color 'm' (magenta) is used for the scatter points.
In this synthetic example, since y is designed to be roughly twice x, you should observe an upward trend in the scatter plot. The histograms would show the distributions of x and y, which should roughly be normal due to our random generation.
This kind of plot is beneficial in understanding correlations, patterns, and potential outliers in bivariate data.
Pairplot
The pairplot function in Seaborn is utilized to plot pairwise relationships in a dataset. By using pairplot, we can instantly visualize the distributions of single variables and relationships between two variables. It's especially useful for exploring datasets.
import seaborn as sns import matplotlib.pyplot as plt # Load the iris dataset iris = sns.load_dataset("iris") # Create a pairplot of the iris dataset sns.pairplot(iris, hue='species', palette='bright') plt.show()import seaborn as sns import matplotlib.pyplot as plt # Load the iris dataset iris = sns.load_dataset("iris") # Create a pairplot of the iris dataset sns.pairplot(iris, hue='species', palette='bright') plt.show()import seaborn as sns import matplotlib.pyplot as plt # Load the iris dataset iris = sns.load_dataset("iris") # Create a pairplot of the iris dataset sns.pairplot(iris, hue='species', palette='bright') plt.show()
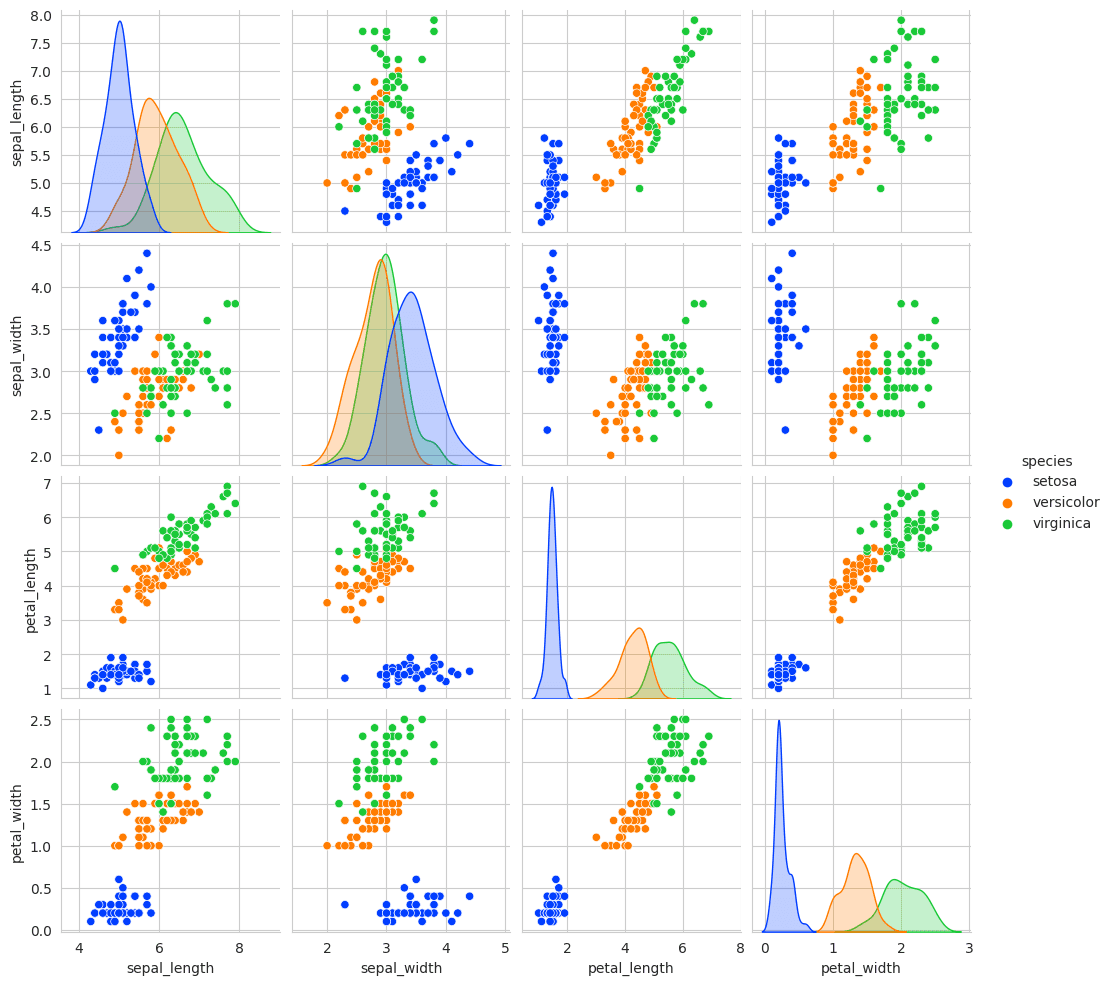
Explanation: In the code above:
We first load the iris dataset, which contains measurements for 150 iris flowers from three different species.
The pairplot function is then used to display a grid of scatter plots for each pair of features in the dataset. The diagonal of this grid shows the distribution of the single feature corresponding to the row or column.
The hue parameter is utilized to color the points by species. This makes it easier to discern the relationship between the measurements and the species of the iris.
We used the palette argument to specify the coloring scheme. In this case, 'bright' is a collection of bright color tones.
The resulting plots provide an immediate visual summary of the relationships in the dataset. For instance, in the iris dataset, one can quickly notice that one species (setosa) is distinctly different from the other two in terms of petal length and petal width. This makes pairplot a powerful tool for preliminary data exploration.
RegPlot
Seaborn's regplot provides a way to plot data and a linear regression model fit. It is a simple interface to fit regression models across conditional subsets of a dataset.
import seaborn as sns import matplotlib.pyplot as plt # Sample data x = [1, 2, 3, 4, 5, 6, 7, 8, 9] y = [1.1, 2.5, 2.9, 3.8, 5.1, 6.3, 6.9, 8.2, 9.1] # Using Seaborn's regplot to plot data and regression model fit sns.regplot(x=x, y=y, color='blue', line_kws={"color": "red"}) plt.title("Seaborn regplot") plt.show() import seaborn as sns import matplotlib.pyplot as plt # Sample data x = [1, 2, 3, 4, 5, 6, 7, 8, 9] y = [1.1, 2.5, 2.9, 3.8, 5.1, 6.3, 6.9, 8.2, 9.1] # Using Seaborn's regplot to plot data and regression model fit sns.regplot(x=x, y=y, color='blue', line_kws={"color": "red"}) plt.title("Seaborn regplot") plt.show() import seaborn as sns import matplotlib.pyplot as plt # Sample data x = [1, 2, 3, 4, 5, 6, 7, 8, 9] y = [1.1, 2.5, 2.9, 3.8, 5.1, 6.3, 6.9, 8.2, 9.1] # Using Seaborn's regplot to plot data and regression model fit sns.regplot(x=x, y=y, color='blue', line_kws={"color": "red"}) plt.title("Seaborn regplot") plt.show()
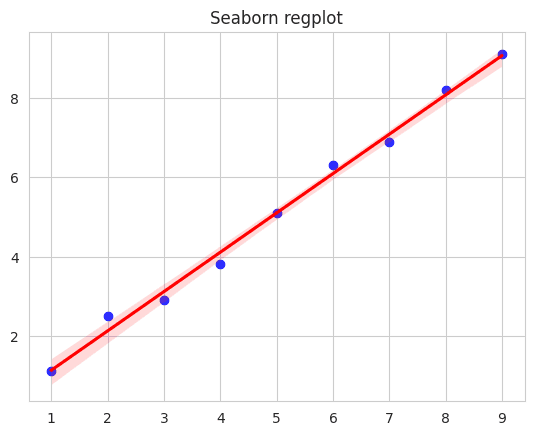
Explanation:
We initialize two lists, x and y, which represent our sample data.
The regplot function is called to plot the relationship between x and y. By default, it also fits a linear regression model and plots the resulting regression line.
We specify the color of the scatter plot and the regression line using the color and line_kws parameters respectively.
The final plot shows individual data points in blue and the linear regression model in red.
The main takeaway from regplot is that it provides a quick glance into how two variables relate linearly. In the provided example, the data points align closely with the red regression line, indicating a strong linear relationship between the x and y variables.
Lmplot
Seaborn's lmplot provides a high-level interface to create scatter plots with regression lines across subsets of data. It's particularly useful when you want to visualize the relationship between two variables while also comparing across subsets of the data based on a categorical variable.
Code: For this demonstration, let's use the inbuilt tips dataset in Seaborn which records the total bill and tip amount, along with the gender and time (Dinner or Lunch) of the diner:
import seaborn as sns import matplotlib.pyplot as plt # Loading the tips dataset tips = sns.load_dataset("tips") # Using Seaborn's lmplot sns.lmplot(x="total_bill", y="tip", data=tips, hue="sex", col="time", markers=["o", "s"], palette="Set1") plt.show() import seaborn as sns import matplotlib.pyplot as plt # Loading the tips dataset tips = sns.load_dataset("tips") # Using Seaborn's lmplot sns.lmplot(x="total_bill", y="tip", data=tips, hue="sex", col="time", markers=["o", "s"], palette="Set1") plt.show() import seaborn as sns import matplotlib.pyplot as plt # Loading the tips dataset tips = sns.load_dataset("tips") # Using Seaborn's lmplot sns.lmplot(x="total_bill", y="tip", data=tips, hue="sex", col="time", markers=["o", "s"], palette="Set1") plt.show()
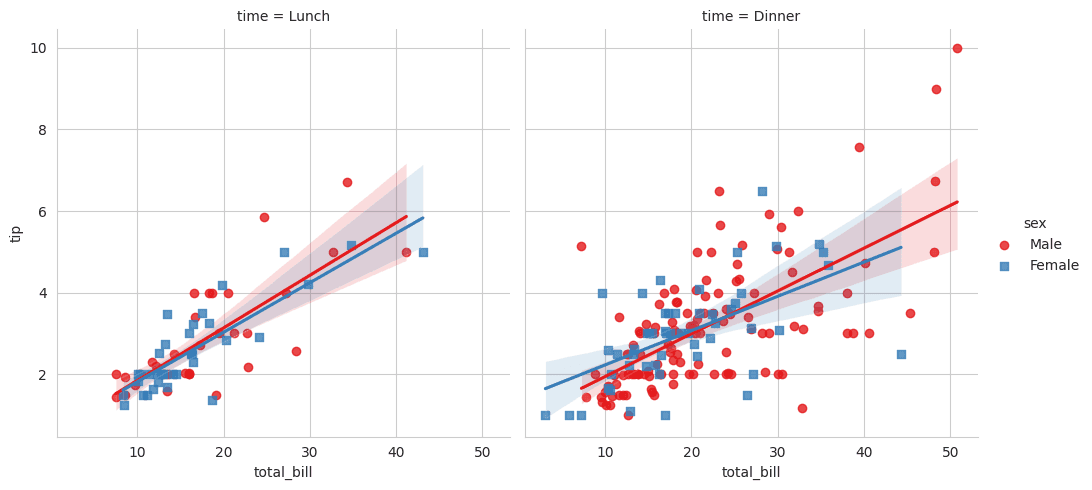
Explanation:
We start by loading the tips dataset using sns.load_dataset("tips").
In the lmplot, the x and y arguments specify the names of the dataframe columns to be plotted on the x and y axes.
The hue argument is used to color the scatter points and regression lines differently for male and female diners. This allows us to see if there's a difference in the relationship between the total bill and tip amount for the two genders.
The col argument creates separate plots based on the time of the meal (Lunch or Dinner).
markers specifies the type of marker for each hue level. Here, "o" is used for male and "s" for female.
Finally, the palette argument specifies the color palette used for plotting.
From the resulting plots, we can observe the relationships between total bill and tip for different genders, and compare these relationships across Lunch and Dinner times. This is the power of lmplot: it allows multi-faceted exploration of data in a concise manner.
Heatmap
A heatmap is a graphical representation of data in which individual values within a matrix are represented as colors. The varying shades of colors in a heatmap provide an immediate visual summary of information. Heatmaps are especially useful for visualizing variance across multiple variables, revealing any patterns, displaying whether individual variables are closely related, and for detecting if there's any correlation between two variables. For instance, in the context of our example, imagine that you have metrics data for different categories, and you want to understand the performance of these metrics across the categories. A heatmap can vividly represent this information, allowing you to identify patterns or anomalies quickly.
import numpy as np import seaborn as sns import matplotlib.pyplot as plt # Set random seed for reproducibility np.random.seed(42) # Generate synthetic data data = np.random.rand(10, 10) # A 10x10 matrix of random values between 0 and 1 # Define labels for rows and columns rows = ['Metric ' + str(i) for i in range(1, 11)] columns = ['Category ' + str(j) for j in range(1, 11)] # Convert data into a DataFrame for better labeling import pandas as pd df = pd.DataFrame(data, index=rows, columns=columns) # Plotting the heatmap sns.heatmap(df, cmap='YlGnBu', annot=True) plt.title('Metrics Across Categories') plt.show()import numpy as np import seaborn as sns import matplotlib.pyplot as plt # Set random seed for reproducibility np.random.seed(42) # Generate synthetic data data = np.random.rand(10, 10) # A 10x10 matrix of random values between 0 and 1 # Define labels for rows and columns rows = ['Metric ' + str(i) for i in range(1, 11)] columns = ['Category ' + str(j) for j in range(1, 11)] # Convert data into a DataFrame for better labeling import pandas as pd df = pd.DataFrame(data, index=rows, columns=columns) # Plotting the heatmap sns.heatmap(df, cmap='YlGnBu', annot=True) plt.title('Metrics Across Categories') plt.show()import numpy as np import seaborn as sns import matplotlib.pyplot as plt # Set random seed for reproducibility np.random.seed(42) # Generate synthetic data data = np.random.rand(10, 10) # A 10x10 matrix of random values between 0 and 1 # Define labels for rows and columns rows = ['Metric ' + str(i) for i in range(1, 11)] columns = ['Category ' + str(j) for j in range(1, 11)] # Convert data into a DataFrame for better labeling import pandas as pd df = pd.DataFrame(data, index=rows, columns=columns) # Plotting the heatmap sns.heatmap(df, cmap='YlGnBu', annot=True) plt.title('Metrics Across Categories') plt.show()
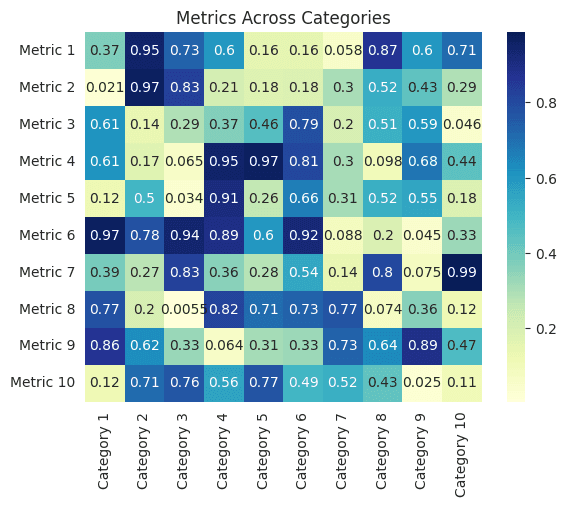
Explanation:
The code begins by importing necessary libraries. We're using numpy for numerical operations, seaborn for advanced plotting, and matplotlib for basic plotting functionalities.
We set a random seed (np.random.seed(42)) to ensure reproducibility. This ensures that the random data generated remains consistent across multiple runs.
Next, we generate a synthetic dataset using np.random.rand, which creates a 10x10 matrix filled with random values between 0 and 1. This data represents metrics across categories.
We then define labels for rows (Metrics) and columns (Categories) to add context to our heatmap.
The raw data is converted into a pandas DataFrame, a versatile data structure that allows for better labeling and easier data manipulation.
Finally, we visualize the data using Seaborn's heatmap function. The cmap parameter specifies the color palette (YlGnBu in this case), and the annot parameter ensures that the individual data points are displayed on the heatmap.
The title is added using plt.title, and the entire visualization is displayed using plt.show(). The resulting heatmap offers a color-coded representation of metrics across different categories, making it easier to discern patterns and relationships between them.
ClusterMap
A clustermap is a specialized type of heatmap used in hierarchical clustering to visualize a dataset in a way that's ordered to highlight patterns in the data. The data is grouped based on similarities, and this grouping is typically represented as a dendrogram (a tree diagram). This technique can provide insights into the structure of data and can help in identifying patterns or clusters within the data.
import numpy as np import seaborn as sns import matplotlib.pyplot as plt # Set random seed for reproducibility np.random.seed(42) # Generate synthetic data data = np.random.rand(10, 10) # A 10x10 matrix of random values between 0 and 1 # Define labels for rows and columns rows = ['Metric ' + str(i) for i in range(1, 11)] columns = ['Category ' + str(j) for j in range(1, 11)] # Convert data into a DataFrame for better labeling import pandas as pd df = pd.DataFrame(data, index=rows, columns=columns) # Plotting the clustermap sns.clustermap(df, cmap='YlGnBu', annot=True, figsize=(10, 10)) plt.suptitle('Hierarchical Clustering of Metrics Across Categories', y=1.02) plt.show()import numpy as np import seaborn as sns import matplotlib.pyplot as plt # Set random seed for reproducibility np.random.seed(42) # Generate synthetic data data = np.random.rand(10, 10) # A 10x10 matrix of random values between 0 and 1 # Define labels for rows and columns rows = ['Metric ' + str(i) for i in range(1, 11)] columns = ['Category ' + str(j) for j in range(1, 11)] # Convert data into a DataFrame for better labeling import pandas as pd df = pd.DataFrame(data, index=rows, columns=columns) # Plotting the clustermap sns.clustermap(df, cmap='YlGnBu', annot=True, figsize=(10, 10)) plt.suptitle('Hierarchical Clustering of Metrics Across Categories', y=1.02) plt.show()import numpy as np import seaborn as sns import matplotlib.pyplot as plt # Set random seed for reproducibility np.random.seed(42) # Generate synthetic data data = np.random.rand(10, 10) # A 10x10 matrix of random values between 0 and 1 # Define labels for rows and columns rows = ['Metric ' + str(i) for i in range(1, 11)] columns = ['Category ' + str(j) for j in range(1, 11)] # Convert data into a DataFrame for better labeling import pandas as pd df = pd.DataFrame(data, index=rows, columns=columns) # Plotting the clustermap sns.clustermap(df, cmap='YlGnBu', annot=True, figsize=(10, 10)) plt.suptitle('Hierarchical Clustering of Metrics Across Categories', y=1.02) plt.show()
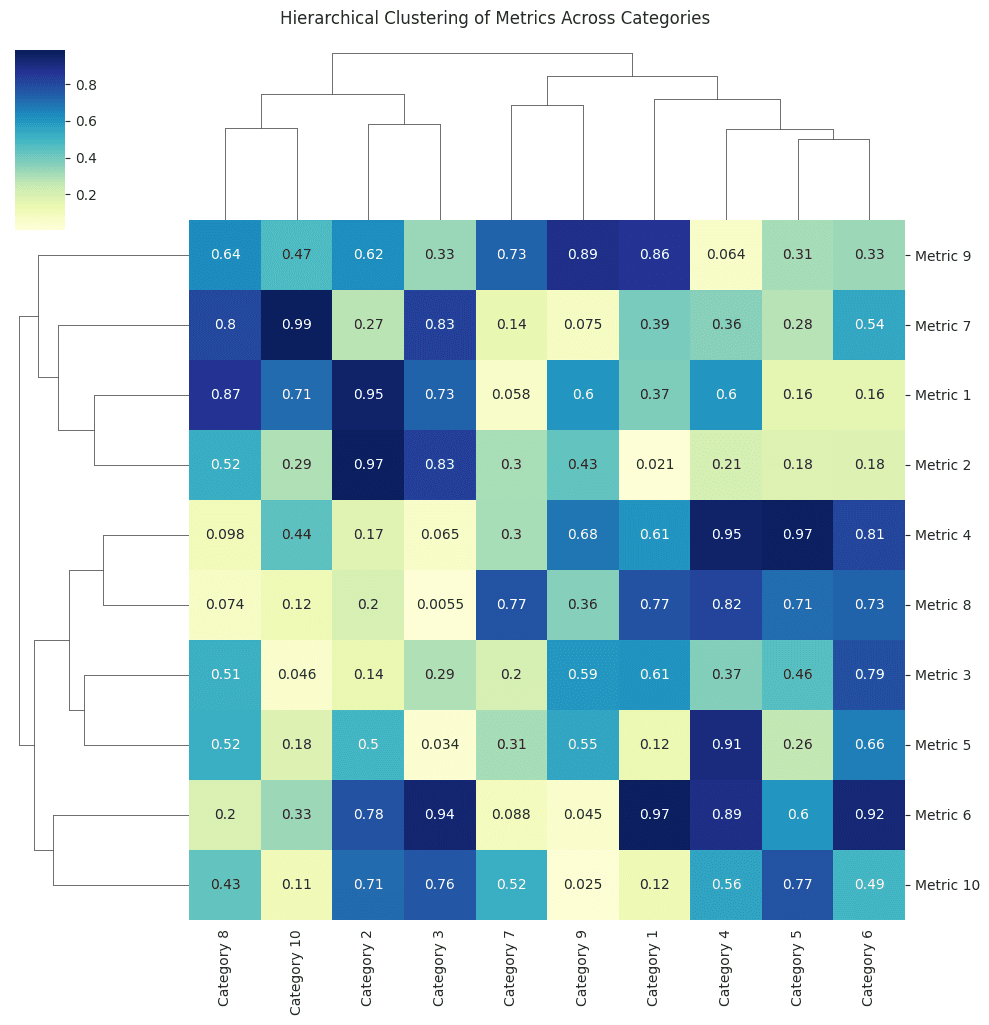
Explanation:
As with the previous example, the code starts by importing necessary libraries.
A random seed is set for consistency in data generation.
We generate a 10x10 matrix filled with random values, simulating metrics data across various categories.
Labels for rows and columns are defined to provide context.
The data is converted into a pandas DataFrame for better data manipulation and labeling.
To visualize the data using hierarchical clustering, Seaborn's clustermap function is used. Similar to the heatmap, the cmap parameter specifies the color palette, and the annot parameter allows data values to be displayed on the map.
A title is added using plt.suptitle. Since clustermaps come with their own title space for the dendrogram, the y parameter in plt.suptitle is adjusted to position the title appropriately.
The final visualization displays not only the heatmap of metrics but also dendrograms on both axes. These dendrograms show the hierarchical grouping of rows and columns based on their similarities. This clustering can help identify which metrics and categories have similar performance or characteristics.
After an exhaustive exploration of various plotting capabilities provided by Seaborn, it is evident that this library offers a rich set of tools for visualizing both relational and categorical data. Whether one is keen on deciphering relationships between variables using scatter or line plots, examining distributions with histograms, KDEs, or ECDFs, or understanding categorical variations through box, violin, or bar plots, Seaborn facilitates clear and aesthetically pleasing visualizations. Additionally, the matrix plots like heatmaps and cluster maps are indispensable for representing large datasets in a condensed manner. The integration of regression analysis in the plotting functions adds another layer of sophistication, allowing for insights into potential predictive relationships within the data. In conclusion, Seaborn stands as a versatile and comprehensive library, providing researchers and data analysts with an expansive toolkit for data exploration, analysis, and storytelling.
Written by Numan Yaqoob, PHD candidate
