
In the financial world, precision in predictive modeling is paramount. Just as a symphony relies on the harmony of multiple instruments to produce a melodious output, machine learning leverages ensemble methods to enhance predictive accuracy. At its core, ensemble methods combine multiple models, offsetting individual biases and reducing overfitting, thus making predictions more robust against the unpredictable nature of financial data. Techniques like Bagging (used in Random Forests), Boosting (seen in algorithms like AdaBoost), and Stacking offer diverse ways to merge model outputs. For finance professionals, this amalgamation translates to more accurate portfolio optimizations, improved credit scoring, sophisticated algorithmic trading strategies, and enhanced risk management, ensuring better decision-making in an ever-evolving market landscape.
1. The Ensemble Philosophy:
Roots in Balancing Variance and Bias:
Every predictive model's performance can be evaluated in terms of its variance and bias. Variance relates to a model's sensitivity and how much its predictions might swing or fluctuate when exposed to different datasets. High variance can lead to wildly different predictions for minor changes in input. Bias, on the other hand, measures how far off a model's predictions are from actual results, regardless of the dataset used. It represents systematic errors in predictions, often stemming from overly simplistic assumptions in the modeling process. Herein lies the genius of ensemble methods. By combining the outputs of multiple models, ensemble methods effectively tame high variance (by averaging out erratic individual predictions) and reduce bias (by ensuring that no single flawed assumption overly influences the final output). Thus, ensemble methods harmonize these two often conflicting error sources, leading to more consistent and accurate predictions.
The Shield Against Overfitting:
One of the common pitfalls in predictive modeling, especially in the intricate landscapes of finance or complex data-driven domains, is overfitting. When a model is overly complex, it might perform exceptionally well on its training data, capturing every minor detail, noise, and anomaly. However, this often comes at the expense of its ability to generalize to new, unseen data. Such models become so entangled with the idiosyncrasies of the training data that they lose their predictive power on fresh datasets. Ensemble methods offer a safeguard against this. By aggregating predictions from diverse models, each with its nuances and potential peculiarities, ensemble methods ensure that no single model's quirks dominate. This aggregation dilutes the over-specific tendencies of individual models, resulting in a final prediction that is more resilient, adaptable, and reliable when faced with new data scenarios.
2. The Ensemble Arsenal:
Bagging (Bootstrap Aggregating):
Unraveling the Bagging Mechanism:
At its essence, bagging is about embracing diversity. By drawing multiple subsets from the original data using random sampling (and allowing replacements), bagging trains several models on these varied data snippets. The collective wisdom of these models — be it an average for continuous outputs or a majority vote for categorical ones — offers a prediction less susceptible to individual model quirks.
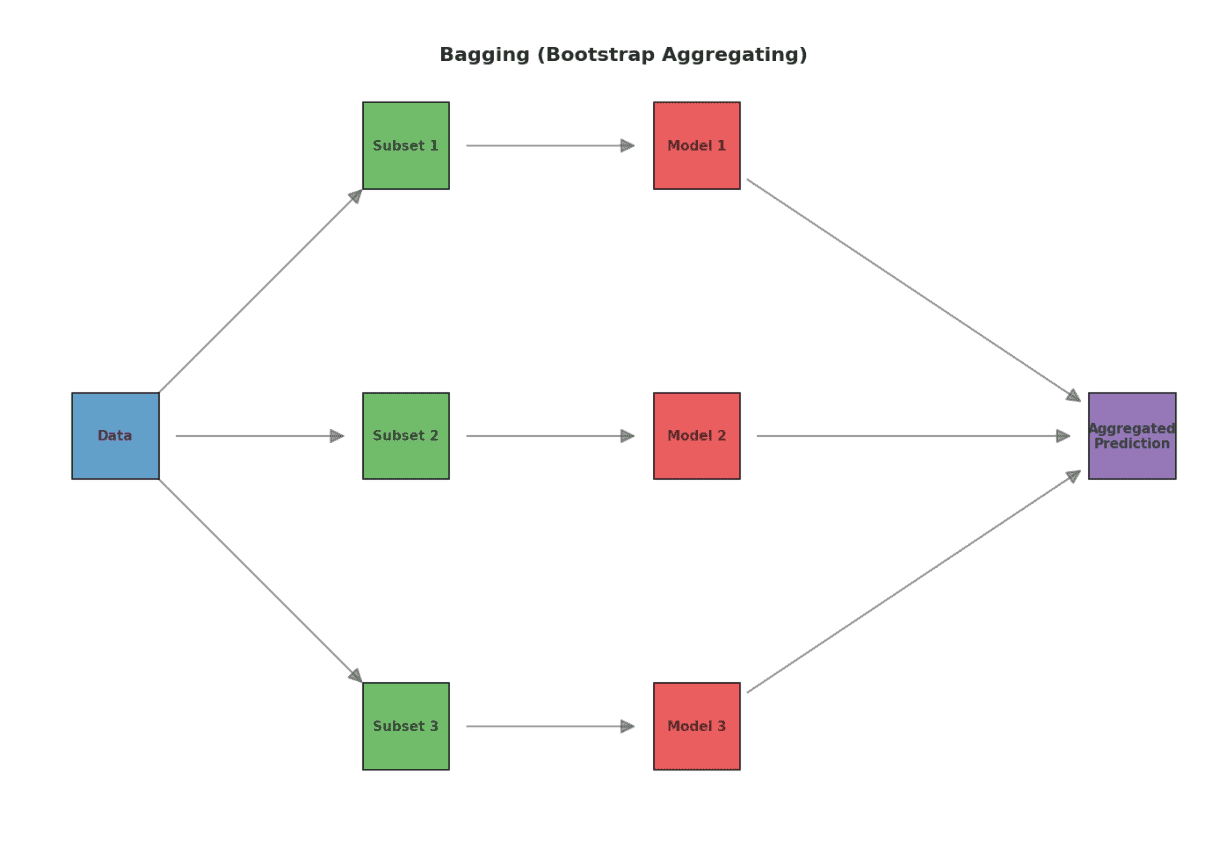
Random Forests in Focus:
Picture a parliament of decision trees, each representing a unique subset of data. These trees individually analyze data, make decisions, and then collaboratively reach a verdict. Random Forests ensure each tree's voice is heard, eventually reaching a decision reflective of the collective.
Boosting:
The Essence of Boosting:
Boosting operates like a diligent student: analyzing past mistakes to do better next time. Models are trained in succession, with each new recruit specifically focusing on the areas where its predecessors faltered. By consistently addressing errors, boosting builds a chain of models that collectively offer a refined prediction.

Key Variants:
AdaBoost (Adaptive Boosting):
Think of AdaBoost as an empathetic teacher. Every time a data instance is misclassified, AdaBoost takes note, ensuring that the next model in line pays extra attention to that instance.
This continuous loop of error identification and correction strengthens the ensemble's predictive prowess.
XGBoost:
Often dubbed the superhero of boosting, XGBoost offers rapid computation, an innate ability to manage sparse data, and in-built mechanisms to avoid overfitting, ensuring models are both fast and accurate.
Stacking (Stacked Generalization):
Decoding Stacking:
In stacking's architectural approach, initial models — the pillars — make their individual predictions. Then, a meta-model, the keystone, reviews these predictions, making the final, more informed decision.
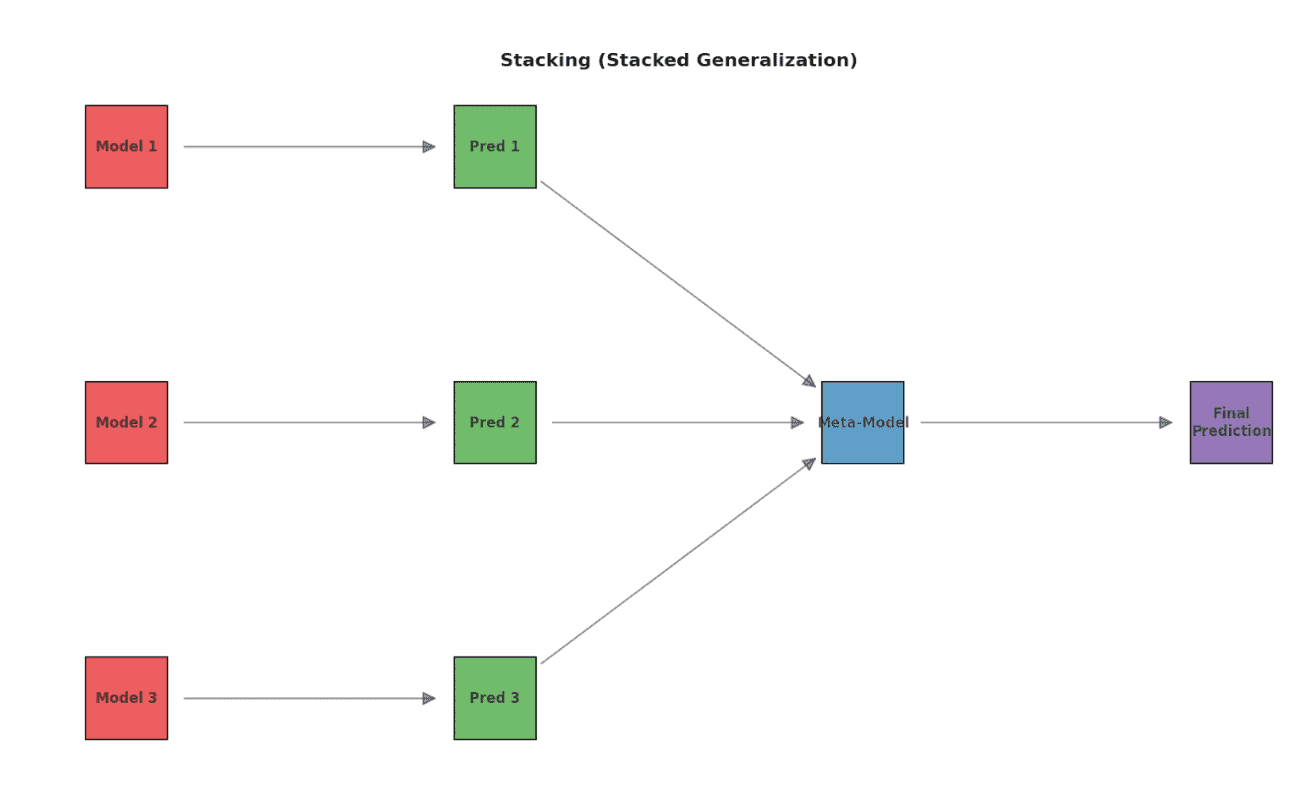
Implementation Nuances:
The process typically begins by dividing the training data. The first chunk is utilized to educate the base models. These models then offer predictions on the second chunk, transforming it into a new dataset. This transformed dataset, with predictions as features, becomes the training ground for the meta-model.
Voting:
The Democratic Algorithm - Hard Voting:
In this method, every model has an equal voice, akin to a democratic election. Each proposes its best solution, and the most popular answer becomes the ensemble's final verdict.
Elevated Insights - Soft Voting:
This approach is reminiscent of a deliberative council meeting. Instead of straightforward votes, models provide probabilities for each class. The ensemble then makes its decision based on the average probability, ensuring a more nuanced and informed outcome.

3. Benefits of the Ensemble Approach:
Accuracy Amplified:
Ensemble methods aren't just a fad in the world of machine learning and data science; they have consistently proven their worth. Combining multiple models allows ensembles to leverage a broader perspective in the decision-making process. Instead of relying on a singular viewpoint from one model, ensembles aggregate insights, leading to more accurate predictions. This is why ensemble methods are often the stars of machine learning competitions, regularly outperforming individual algorithms. By effectively harmonizing multiple perspectives, ensemble methods stand tall, often surpassing the accuracy thresholds set by single-model benchmarks.
The Robustness Factor:
Imagine a panel of experts discussing a challenging problem. If one expert makes an erroneous assumption, the others can correct it. Similarly, ensemble methods pool the judgments of multiple models. The beauty of this approach is that even if one or a few models in the ensemble make poor predictions due to noise, outliers, or inherent biases, the collective wisdom of the remaining models can compensate. This collective approach acts as a safety net, ensuring that the ensemble remains robust even when individual models falter. This distribution of reliance means that ensembles are generally more stable and less prone to the overfitting that might plague a single, overly complex model.
A Spectrum of Strengths:
Every algorithm, be it decision trees, neural networks, support vector machines, or any other, comes with its own set of strengths and weaknesses. These algorithms might excel in certain situations while underperforming in others. When you create an ensemble, you're essentially forming a team of these algorithms. Each member of this team brings its unique strengths to the table. The ensemble method ensures that the team collaboratively capitalizes on individual strengths while mitigating the impact of individual weaknesses. For instance, while one model might be sensitive to outliers, another could be more resistant. When these models work together in an ensemble, they ensure that the final prediction benefits from both sensitivities, resulting in a more holistic, balanced, and nuanced prediction.
4. Challenges in the Ensemble Landscape:
The Complexity:
Building an ensemble method is much like constructing a modern, intricate machine with many moving parts. While the final product offers powerful capabilities, its complexity grows with every additional component. In the world of ensembles, every new model added increases the intricacy. Managing such a multi-faceted system, especially during deployment, can be a daunting task. Maintenance issues can arise, where small glitches in one model might cascade, affecting the entire ensemble's performance. Moreover, the computational resources required for executing these intricate ensembles in real-time applications might be substantial, potentially complicating deployments in resource-constrained environments.
Time and Computational Constraints:
Imagine training a machine learning model; now imagine doing that multiple times and then integrating the results. This is the reality of ensemble methods. Training one model can be resource-intensive and time-consuming, depending on the complexity of the model and the size of the data. With ensembles, this effort multiplies. Techniques like boosting or stacking, which involve training models in a sequence or at multiple layers, can be particularly demanding. This sequential nature often means that you can't take advantage of parallel processing to the same extent as with simpler methods like bagging. Consequently, ensemble methods might be out of reach for projects with tight computational budgets or strict turnaround times.
Python, through its Scikit-learn library, provides a rich toolkit for building ensemble models. This approach is based on the idea that combining predictions from various models can improve the overall prediction accuracy. Let's start with data loading
Application of Ensembled model using python
We will now implement ensemble techniques such as bagging, boosting, stacking, and the voting model on Bitcoin stock data. The data will be sourced from the openBB library, and we will proceed with a step-by-step application using relevant Python libraries like Scikit-learn provides a rich toolkit for building ensemble models. We will provide a thorough, step-by-step breakdown of how to implement each of these ensemble techniques, guiding the reader through the particulars of each approach and will compare results with model evaluation methods like Mean absolute error (MAE). Let's start with loading the data.
Installing openbb and Loading data
Installing the openbb package:
It installs the openbb package using pip, which is the package manager for Python. The openbb package is not part of the standard Python library, so it needs to be installed before you can use it.
Importing the required module:
Here, you're importing the openbb module from the openbb_terminal.sdk package. This module contains the necessary functions and classes to interact with the services provided by the OpenBB terminal.
Loading cryptocurrency trading data:

We are using the load method of the crypto attribute of the openbb module, indicating that we want to fetch cryptocurrency trading data.
The symbol argument specifies that we are interested in Bitcoin (BTC).
The to_symbol argument indicates that you want trading data for Bitcoin in terms of USDT (Tether), which is a stablecoin pegged to the US Dollar.
The source argument indicates that the data should come from CCXT, which is a unified cryptocurrency trading library that provides a way to access data from many different exchanges.
The exchange argument specifies that we want the data from the 'bitcoincom' exchange specifically.
Finally, the start_date argument ensures that we get trading data starting from January 1, 2022.
Preparing Data for Bitcoin Price Prediction
In the given code, we're preparing Bitcoin's historical trading data, stored in the btc_usdtDataFrame, for a predictive modeling task using the scikit-learn library. The objective is to predict the 'Close' price of Bitcoin. To achieve this, we segregate the dataset into input features (X), which consists of all columns except the 'Close' price, and the target (y), which is solely the 'Close' price. The train_test_split function then partitions these datasets into training and test sets. Importantly, the shuffle=False parameter ensures the time series data isn't randomized, preserving the chronological order, which is crucial for accurate time series forecasting.
1-Bagging (Bootstrap Aggregating):
Hyperparameter Tuning for Random Forest Regressor
In the provided code, we're optimizing a Random Forest model for our Bitcoin price prediction task. Specifically, we are performing hyperparameter tuning, a crucial step in machine learning that involves finding the best set of parameters for our model to improve its performance.
GridSearchCV:
This is a utility from scikit-learn used for exhaustive search over a specified parameter grid. Grid search cross-validates as it scans through each combination of hyperparameters to find the optimal set.
Random Forest Regressor:
This is a regression algorithm based on the ensemble learning method. It creates a 'forest' of decision trees during training and makes predictions by averaging the outputs of individual trees.
Hyperparameter Grid:
param_grid_rf: This dictionary defines the hyperparameters we want to tune, along with potential values for each.
n_estimators: Number of trees in the forest.
max_features: The number of features to consider when looking for the best split.
max_depth: Maximum depth of the tree.
min_samples_split: Minimum number of samples required to split an internal node.
min_samples_leaf: Minimum number of samples required to be at a leaf node.
Grid Search Initialization:
grid_search_rf: Here we initialize the GridSearchCV object.
The model to be tuned is specified as RandomForestRegressor().
param_grid_rf contains the hyperparameters to be tuned.
cv=3 indicates a 3-fold cross-validation.
n_jobs=-1 means that the computation will be dispatched on all the CPUs of the computer.
verbose=2 makes the grid search output more detailed.
scoring='neg_mean_squared_error' indicates that we're using the negative mean squared error as a metric. A model with a higher (less negative) value is better.
Fit and Fetch Best Model:
grid_search_rf.fit(X_train, y_train): This line starts the grid search process. The algorithm will iterate through every combination of hyperparameters specified in param_grid_rf on the X_train and y_train datasets.
best_rf = grid_search_rf.best_estimator_: After fitting, the best model (with the best combination of hyperparameters) is stored in the best_rf variable.
2. Boosting:
Hyperparameter Tuning for AdaBoost Regressor
The code segment aims to optimize the AdaBoost Regressor, another ensemble learning model, for predicting Bitcoin's 'Close' price. AdaBoost, short for "Adaptive Boosting", adjusts weights of the observations to focus on challenging cases, boosting the overall performance by combining weak learners into a strong learner.
AdaBoostRegressor:
This is a regression model from scikit-learn that fits a series of weak learning models (typically decision trees) on various weight-adjusted versions of the dataset and uses averaging to make predictions.
Hyperparameter Grid:
param_grid_ada: This dictionary outlines the hyperparameters we wish to optimize and their potential values:
n_estimators: Specifies the number of weak learners to train. It denotes the number of boosting stages to be run.
learning_rate: This shrinks the contribution of each weak learner. There's a trade-off: a smaller value requires more boosting stages, but the predictions generalize better.
Grid Search Initialization:
grid_search_ada: This initializes the GridSearchCV object.
The model to be optimized is specified as AdaBoostRegressor().
param_grid_ada provides the hyperparameters to be tested.
cv=3 performs a 3-fold cross-validation.
n_jobs=-1 ensures that all available CPUs on the machine are used for computation.
verbose=2 provides a detailed grid search output.
scoring='neg_mean_squared_error' indicates that the negative mean squared error is our evaluation metric, with a higher (less negative) score indicating a better model.
Fit and Fetch Best Model:
grid_search_ada.fit(X_train, y_train): This triggers the grid search process, iterating over each combination of hyperparameters in param_grid_ada using the training data.
best_ada = grid_search_ada.best_estimator_: Post fitting, the best-performing model, based on the combination of hyperparameters, is saved into the best_ada variable.
Hyperparameter Tuning for XGBoost Regressor
The provided code is set to refine the XGBoost Regressor, an advanced gradient boosting algorithm, to optimally predict Bitcoin's 'Close' price. XGBoost stands for "Extreme Gradient Boosting", renowned for its performance and speed.
xgboost as xgb:
The XGBoost library provides a highly efficient, scalable, and versatile gradient boosting system.
Hyperparameter Grid:
param_grid_xgb: A dictionary that details the hyperparameters we aim to fine-tune along with their potential values:
learning_rate (or eta): Controls the contribution of each tree in the ensemble. Smaller values make the optimization more robust.
n_estimators: Represents the number of gradient boosted trees to be trained.
max_depth: Maximum depth of a tree. Increasing this value makes the model more complex and likely to overfit.
subsample: Fraction of samples used per tree. Setting it to a value less than 1 can prevent overfitting.
colsample_bytree: Fraction of features that can be selected for building the tree during training.
Grid Search Initialization:
grid_search_xgb: Initializes the GridSearchCV object.
The model chosen for optimization is xgb.XGBRegressor(objective='reg:squarederror'), an XGBoost regression model with a squared error regression objective.
param_grid_xgb contains the hyperparameters to be adjusted.
cv=3 denotes a 3-fold cross-validation.
n_jobs=-1 ensures full utilization of the computer's CPUs during the computation.
verbose=2 provides an extended output for the grid search.
scoring='neg_mean_squared_error' sets the negative mean squared error as the evaluation metric. A model with a higher (less negative) score is preferable.
Fit and Retrieve Best Model:
grid_search_xgb.fit(X_train, y_train): Initiates the grid search, navigating through every combination of hyperparameters in param_grid_xgb on the training data.
best_xgb = grid_search_xgb.best_estimator_: After the fitting process, the top-performing model, based on the hyperparameter combinations, is stored in the best_xgb variable.
3. Stacking (Stacked Generalization):
Stacking Regressor Model Optimization
This code segment explores the technique of Stacking, a high-level ensemble method that combines multiple machine learning models to achieve potentially better predictive performance. By using base models (like Random Forest, AdaBoost, and XGBoost) as first-level learners and a meta-model (in this case, Ridge Regression) to combine their predictions, stacking attempts to leverage the strengths of both individual and combined models.
Imports:
StackingRegressor: This model from scikit-learn is an ensemble learning method that combines multiple regression models via a meta-regressor.
Ridge: Represents Ridge Regression, a linear regression model with L2 regularization.
Base Learners Configuration:
base_learners: This list is composed of tuples, each containing an identifier string and a previously optimized model (like best_rf, best_ada, and best_xgb).
Hyperparameter Grid for Meta-learner:
param_grid_stack: This dictionary lists the hyperparameters to be fine-tuned for the meta-learner, which is the Ridge Regression model in this context. The hyperparameter alpha is for regularization strength. Larger values specify stronger regularization.
Stacking Regressor Initialization:
stack_reg: The StackingRegressor is initialized using the base learners and the Ridge regression model as the final estimator (meta-model).
Grid Search for Meta-learner Optimization:
grid_search_stack: Initializes the GridSearchCV object for optimizing the Ridge Regression model hyperparameters.
The model defined for tuning is stack_reg.
param_grid_stack contains the hyperparameters to be tested.
cv=3 represents a 3-fold cross-validation.
cv=3 represents a 3-fold cross-validation.
n_jobs=-1 allows the computation to utilize all available CPUs.
verbose=2 results in an expanded output of the grid search.
scoring='neg_mean_squared_error' specifies the negative mean squared error as the metric, with higher (less negative) scores indicating better models.
Fit and Determine Best Model:
grid_search_stack.fit(X_train, y_train): Activates the grid search, iterating through the hyperparameters of the Ridge regression model using the training data.
best_stack = grid_search_stack.best_estimator_: Post fitting, the optimal Stacking Regressor model, configured with the best hyperparameters for the Ridge Regression meta-model, is saved to best_stack.
4-Implementation of Voting Regressor
The snippet demonstrates the creation and training of a Voting Regressor, which is an ensemble model that merges the predictions from multiple regression models. The fundamental idea behind it is that combining the predictions of several models can lead to a more accurate and robust prediction than relying on a single model.
Imports:
VotingRegressor: This model from scikit-learn combines predictions from multiple regression estimators to improve generalizability and robustness over a single estimator.
Initialization of Voting Regressor:
voting_reg: The VotingRegressor is initialized with a list of tuples. Each tuple has: A unique name for the regression model.
Here, three models are used: RandomForestRegressor, AdaBoostRegressor, and XGBoost'sXGBRegressor. Each model is initialized with 100 estimators (or trees).
The ensemble will combine the predictions of these three models to produce its final prediction.
Training the Voting Regressor:
voting_reg.fit(X_train, y_train): This fits the ensemble model using the training data. This will internally fit each of the three specified regression models on the training data.
Making Predictions:
vote_pred = voting_reg.predict(X_test): After training, the ensemble is used to predict the outputs for the test data. For each instance in the test set, each of the three regression models makes a prediction. The VotingRegressor then averages these predictions (in case of regression) to produce the final prediction for that instance.
Predictions with Optimized Models
This section of the code uses the best optimized models from earlier hyperparameter tuning and stacking processes to make predictions on the test set. The goal is to evaluate each model's performance on unseen data.
Random Forest Predictions:
rf_pred_tuned = best_rf.predict(X_test): The optimized Random Forest model (best_rf) is used to make predictions on the test set, and the results are stored in the rf_pred_tuned array.
AdaBoost Predictions:
ada_pred_tuned = best_ada.predict(X_test): Similarly, the optimized AdaBoost model (best_ada) predicts the values for the test set, and the predictions are stored in the ada_pred_tuned array.
XGBoost Predictions:
xgb_pred_tuned = best_xgb.predict(X_test): The optimized XGBoost model (best_xgb) also makes predictions on the test set, which are stored in the xgb_pred_tuned array.
Stacking Regressor Predictions:
stack_pred_tuned = best_stack.predict(X_test): Finally, the optimized Stacking Regressor model (best_stack) predicts the test set's values. The predictions are stored in the stack_pred_tuned array.
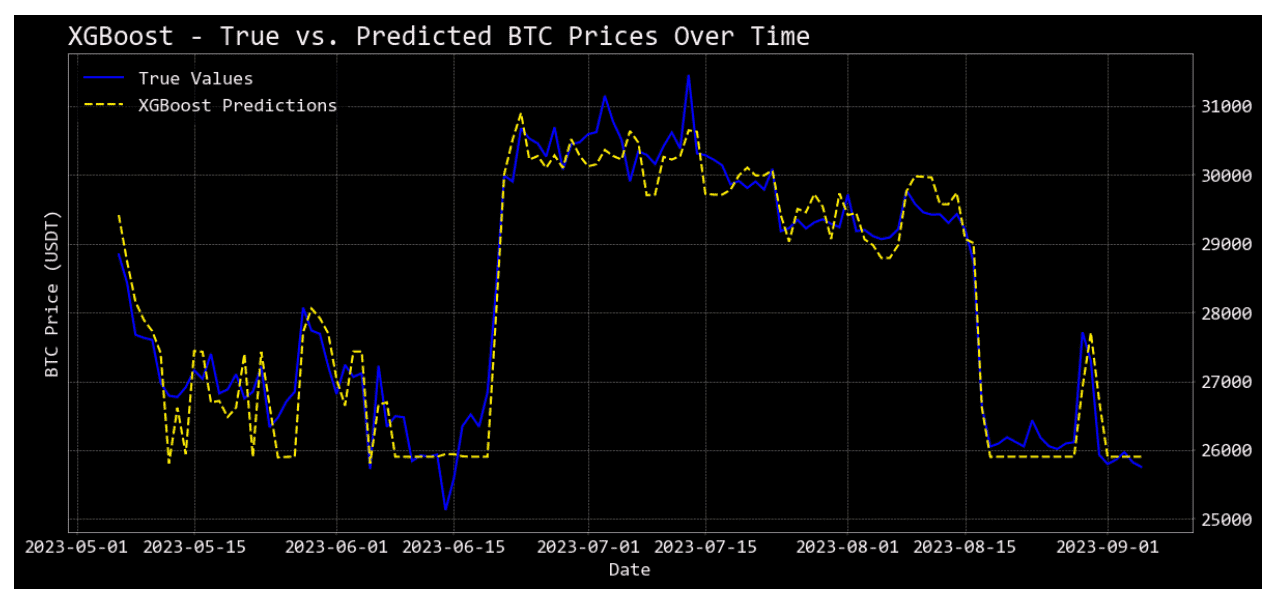
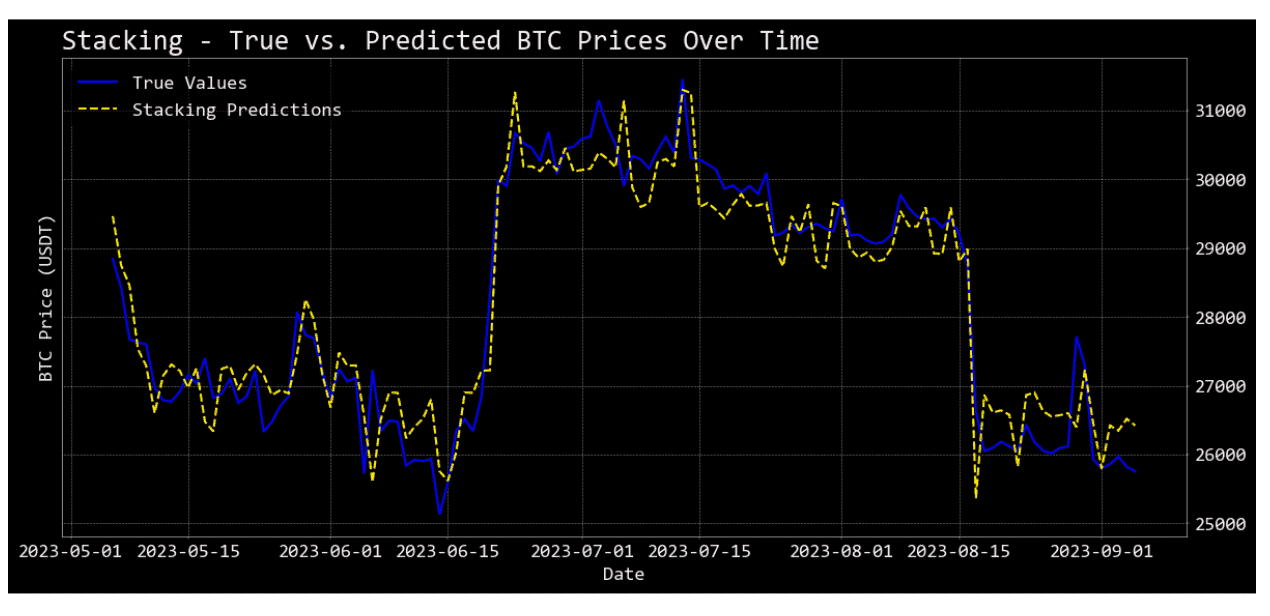
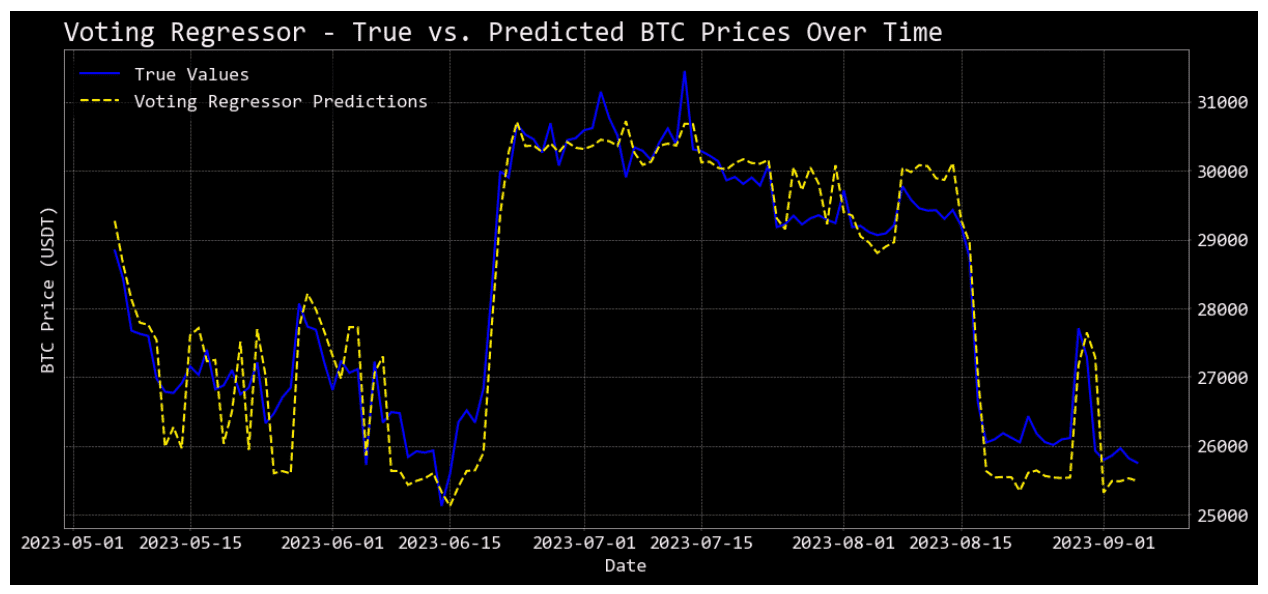
Visualizing Model Predictions
The code snippet showcases a simple yet effective way to visually compare the predictions of different regression models against actual values, particularly in a time-series context (like Bitcoin price predictions over time).
Importing Necessary Libraries:
import matplotlib.pyplot as plt: The Matplotlib library is used for creating visualizations in Python.
Function to Plot Predictions:
plot_predictions(model_name, predictions): This function generates a line plot to juxtapose the real Bitcoin prices against the predictions of a given model.
model_name: A string representing the name of the regression model.
predictions: The array containing predicted values by the model.
Within the function:
A new figure is created with a specified size (figsize).
The true values (y_test) are plotted with a blue solid line.
Predicted values are plotted with a dashed line.
Titles, labels, and legends are added to make the plot more descriptive.
Plotting Each Model's Predictions:
The plot_predictions function is called repeatedly for each model to visualize how their predictions match up against the real values:
plot_predictions("Random Forest", rf_pred_tuned): Plots the predictions of the optimized Random Forest model.
plot_predictions("AdaBoost", ada_pred_tuned): Plots the predictions of the optimized AdaBoost model.
plot_predictions("XGBoost", xgb_pred_tuned): Plots the predictions of the optimized XGBoost model.
plot_predictions("Stacking", stack_pred_tuned): Plots the predictions of the optimized Stacking Regressor model.
plot_predictions("Voting Regressor", vote_pred): Plots the predictions of the Voting Regressor model.

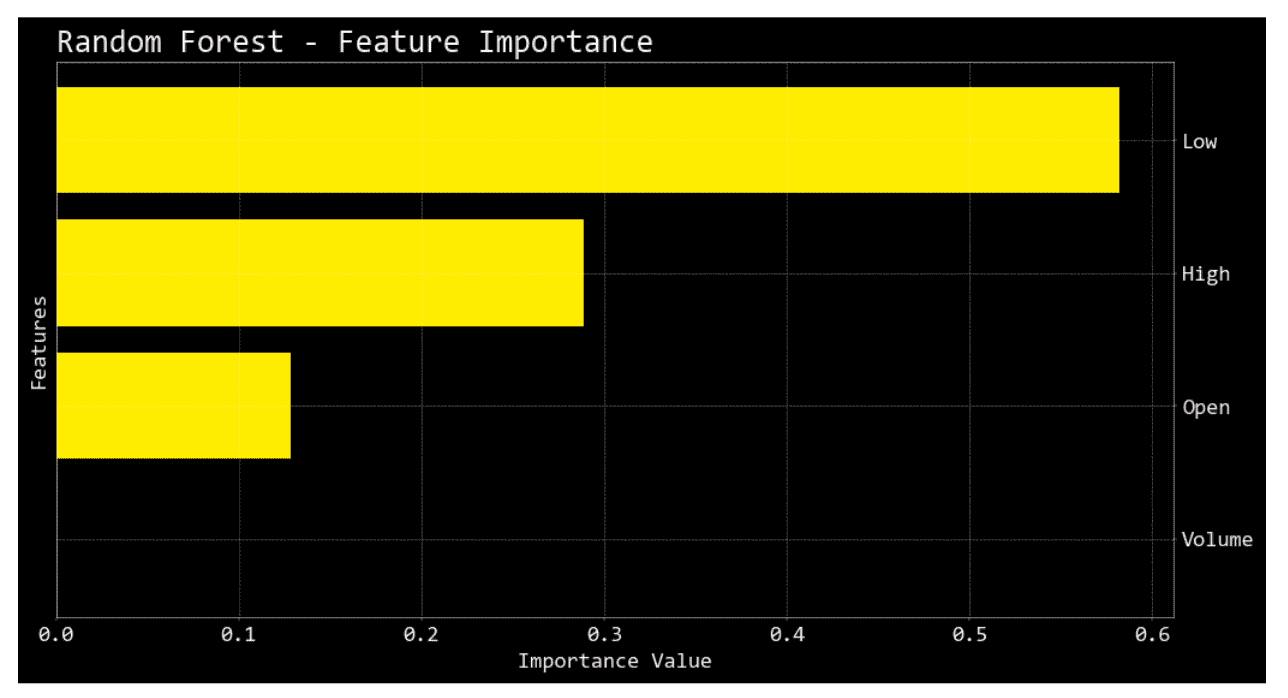
Visualizing Feature Importance
The provided code aims to graphically represent the importance of each feature in the dataset based on how much they impact the model's predictions. This kind of visualization can be incredibly useful for understanding which features are most influential in the prediction process.
Function to Plot Feature Importance:
plot_feature_importance(importance, names, model_name): This function generates a horizontal bar chart representing the importance of each feature.
importance: A list or array that contains importance scores of each feature.
names: Names of the features.
model_name: A string representing the name of the regression model for the title of the plot.
Inside the Function:
feature_importance = list(zip(names, importance)): Pairs feature names with their importance scores.
sorted_feature_importance = sorted(...): Sorts the paired list based on importance scores in descending order. This ensures that when plotted, the most important features are easily discernible.
names, vals = zip(*sorted_feature_importance): Unzips the sorted list to separate names and their values.
The subsequent lines generate a horizontal bar chart using the Matplotlib library. The most important feature will be at the top due to the invert_yaxis() function.
Plotting Feature Importance for Specific Models:
plot_feature_importance(best_rf.feature_importances_, X_train.columns, "Random Forest"): Plots feature importance for the optimized Random Forest model. The feature_importances_ attribute of the Random Forest model provides the importance of each feature.
plot_feature_importance(best_xgb.feature_importances_, X_train.columns, "XGBoost"): Plots feature importance for the optimized XGBoost model. Similarly, the feature_importances_ attribute of the XGBoost model provides the importance of each feature.

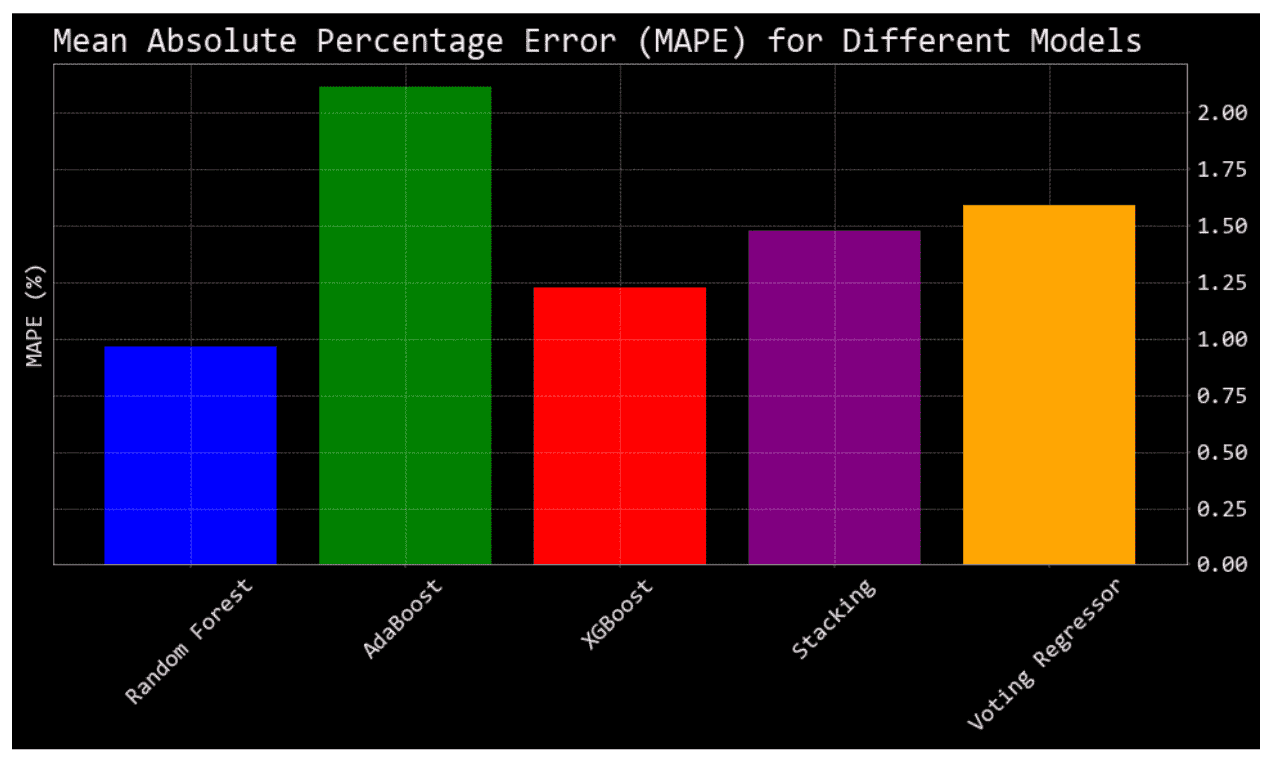
Evaluating Model Performance with MAPE
In this section of the code, the performance of various regression models is evaluated using the Mean Absolute Percentage Error (MAPE) metric. MAPE quantifies the accuracy of a predictive model in terms of the relative error, expressed in percentage.
Function to Compute MAPE:
compute_mape(y_true, y_pred): This function calculates the MAPE between the true values and predicted values.
Handling Zero Division: Before calculating the percentage error, the function identifies and filters out instances where the true value (y_true) is zero to avoid dividing by zero.
Calculating MAPE for Each Model: For each model, the MAPE is computed using the predictions and true values from the test set.
Visualization:
A bar chart is plotted displaying the MAPE values of each model. This visualization aids in quickly identifying which model performed best in terms of MAPE.
Each model's name is placed on the x-axis, while its corresponding MAPE value is on the y-axis. Different colors are used for each model to differentiate them.
The x-tick labels (model names) are rotated by 45 degrees for better visibility.
Printed Results: For clarity and precision, the MAPE values for each model are printed out in a formatted manner.
Predicting the Next Day's BTC Closing Price Using Random Forest
Random Forest:
The objective of the code snippet is to predict the closing price of Bitcoin (BTC) in USDT (a stablecoin usually pegged to the US dollar) for the next day, using the best-performing Random Forest model that has been trained earlier.
Selecting Data for the Next Day:
next_day_row = btc_usdt.iloc[-1:]: This extracts the last row of the btc_usdt dataset, representing the most recent data entry (typically the current day's information).
Preparing the Features:
next_day_data = next_day_row.drop(columns=['Close']): Removes the 'Close' column, which represents the BTC's closing price. This is done because this is the value we aim to predict. In essence, we are isolating the independent variables or features for our prediction model.
Extracting the Date:
next_day_date = next_day_row.index[0].strftime('%Y-%m-%d'): Retrieves the date of the selected data row, formatted as 'Year-Month-Day' (e.g., '2023-09-05').
Predicting Using the Random Forest Model:
next_day_pred_rf = best_rf.predict(next_day_data): Uses the predict method of our previously optimized Random Forest model (best_rf) to forecast the BTC closing price for the next day.
Displaying the Prediction:
The print statement outputs the predicted closing price using the Random Forest model for the next day.

Final Thoughts:
Cryptocurrency, with its notorious unpredictability, presents a tantalizing challenge for predictive modeling. However, as demonstrated, machine learning provides robust tools to tackle this challenge. By employing a combination of diverse algorithms and rigorous evaluation techniques, we can glean valuable insights and make informed predictions. It's essential to remember that while machine learning offers powerful predictive capabilities, external factors and market dynamics can influence cryptocurrency prices. Hence, any predictions should be taken as guiding insights rather than definitive outcomes. For anyone keen on diving into the realm of financial predictions, this blog serves as a foundational blueprint. By understanding the principles and methodologies highlighted here, you can further explore and adapt these techniques to other financial markets or go deeper into advanced predictive modeling for cryptocurrencies see blog.
The full working code for the examples above can be found in the PyFi GitHub Repo.
Written by Numan Yaqoob, PHD candidate