
Linear trend and regression are foundational concepts in statistical modeling. A linear trend refers to a steady and consistent pattern in data, often revealing a constant rate of change over time. Linear regression, on the other hand, is a statistical method used to analyze and model the relationship between a dependent variable and one or more independent variables by fitting a linear equation to the observed data. Together, they provide essential tools for understanding underlying patterns in data, predicting future outcomes, and uncovering relationships between variables. Whether used in finance, economics, science, or other fields, recognizing linear trends and applying linear regression can lead to valuable insights and informed decision-making.
Linear Trend
A linear trend refers to a consistent, straight-line pattern in a dataset over time. It can be observed in time-series data where a variable follows an upward or downward linear trajectory. The linear trend can be described by a straight-line equation:
Here, Y is the value of the variable at time t, a is the y-intercept, and b is the slope of the line, indicating the rate of change over time. The linear trend is often used to describe a consistent growth or decline in economic indicators, sales, population growth, and other time-dependent phenomena.
Regression Analysis
Regression analysis is a statistical method used to model the relationship between a dependent variable (also known as the outcome or target variable) and one or more independent variables (also known as predictors or features). By fitting a mathematical equation to the observed data, it allows you to make predictions, understand underlying patterns, and investigate the relationship between different variables.
There are several types of regression analysis, including:
Linear Regression:
Models the relationship between the dependent variable and independent variables by fitting a linear equation to observed data. The simplest form is simple linear regression, which relates two variables by a straight line.
Multiple Regression:
Extends simple linear regression to include two or more independent variables.
Logistic Regression:
Used when the dependent variable is categorical, often binary (e.g., yes/no, true/false). It models the probability that the dependent variable belongs to a particular category.
Polynomial Regression:
An extension of linear regression that models the relationship between the dependent variable and independent variables as an nth degree polynomial.
Ridge and Lasso Regression:
Specialized versions of linear regression that include regularization terms to prevent overfitting.
Nonlinear Regression:
Utilizes nonlinear functions to model more complex relationships between variables that cannot be fitted by a linear model.
Regression in the context of finance refers to the statistical technique of modeling the relationship between different financial variables. This can be used to understand connections and dependencies, predict future trends, or make decisions based on quantitative analysis.
Simple Linear Regression
Linear Regression, or Simple Linear Regression, examines the relationship between two variables: one independent variable (predictor) and one dependent variable (outcome). The relationship is modeled as a straight line:
Y: Dependent variable
X: Independent variable
β0: y-intercept (constant)
β1: Slope (effect of x on y)
ε: Random error term
Multiple Regression
Multiple Regression extends the concept of Simple Linear Regression to include two or more independent variables. The model is represented as:
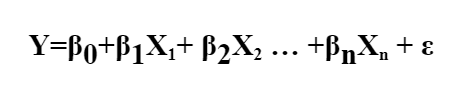
y: Dependent variable
X1, X2…, Xn: Independent variables
β0: y-intercept (constant)
β1, β2,…,βn: Slopes (effects of independent variables on y)
ε: Random error term
Relationship Between Linear Trend and Linear Regression
A linear trend can be modeled using linear regression by treating time as the independent variable and the variable of interest as the dependent variable. In other words, linear regression can be employed to quantify the linear trend in a time-series dataset. The estimated slope β1 will represent the rate of change in the dependent variable over time, capturing the linear trend.
Applications of Linear Trend and Regression in Finance:
Regression analysis serves as an essential tool in various financial applications. By analyzing historical data, it can elucidate the relationships between different investment assets and market factors, enabling the identification and quantification of risks tied to various financial products. This understanding assists in portfolio management, where regression's insights into asset correlations and economic factors aid investors in optimizing their portfolios for desired returns and minimized risks. In pricing models, regression's role is pivotal, and it underlies the estimation of various financial instruments like options and bonds, as evidenced by the famous Black-Scholes model. Further, regression is leveraged for market forecasting, allowing financial professionals to anticipate stock market trends or the future trajectory of interest rates by discerning relationships between economic indicators like interest rates, inflation, and GDP growth. Within the banking sector, regression analysis informs credit scoring by modeling the relationship between loan applicant characteristics and default likelihood, guiding lending decisions and interest rate determinations. It also plays a crucial role in the estimation of the Capital Asset Pricing Model (CAPM), a core concept in finance that describes the connection between an asset's expected return and its market sensitivity, thereby informing appropriate return rates. Economists and financial analysts also employ regression to gauge how economic policy shifts or global events might influence stock prices, interest rates, or other financial indicators. Finally, in the fast-paced world of high-frequency trading, regression models can be applied to predict price movements on exceedingly short time frames, based on recent trading data analysis.
Assumptions of Linear Regression
When you decide to analyze your data using linear regression, part of the process entails ensuring that the data you wish to analyze can indeed be examined using this method. Linear regression requires that your data meet seven specific assumptions, and checking for these is vital for obtaining valid results. These assumptions are:
Assumption #1: Your dependent variable must be measured at the continuous level (i.e., either an interval or ratio variable). Examples might include hours of study, IQ score, exam performance, weight, etc.
Assumption #2: The independent variable(s) must also be measured at the continuous level (e.g., interval or ratio variables).
Assumption #3: A linear relationship must exist between the variables. You can check this by creating a scatterplot in Python and visually inspecting it for linearity. If the relationship is not linear, you may need to run a non-linear regression analysis, perform polynomial regression, or transform your data within Python.
Assumption #4: There should be no significant outliers. Outliers can negatively affect the regression analysis, reducing the fit of the regression equation and predictive accuracy. Within Python, you can use various statistical techniques to detect and possibly handle outliers.
Assumption #5: Observations must be independent, which you can check using the Durbin-Watson statistic or similar tests available in Python libraries. This tests the assumption of no autocorrelation in the residuals.
Assumption #6: Your data must display homoscedasticity, where the variances along the line of best fit remain similar. If this is not the case (i.e., heteroscedasticity is present), it can be visually inspected through residual plots in Python, and further steps might be needed to remedy this.
Assumption #7: The residuals of the regression line must be approximately normally distributed. In Python, you can check this assumption using methods like histograms with a superimposed normal curve or a Q-Q plot.
Do not be surprised if, when analyzing your real-world data, one or more of these assumptions is violated. This is common, and fortunately, Python provides a host of tools and methods that can help to diagnose and overcome these issues. Careful consideration and handling of these assumptions in Python can help you arrive at more accurate and meaningful insights from your linear regression analysis.
Linear Regression using Python
In today's data-driven world, the ability to extract meaningful insights from vast amounts of information is invaluable. One of the fundamental techniques in predictive modeling and data analysis is linear regression. It helps in understanding the linear relationship between the dependent and one or more independent variables, offering a simple yet powerful way to predict outcomes. Utilizing the powerful programming language Python, which has become a staple in the field of data science, performing linear regression is more accessible than ever. With a rich ecosystem of libraries such as scikit-learn and statsmodels, Python provides an efficient pathway for data professionals to implement and interpret linear regression models. In this blog post, we will explore how to conduct linear regression analysis using Python, making this valuable statistical method available to anyone interested in diving into the world of data analytics.
Predicting Median Home Values in California
The task of predicting housing prices is a classic problem in Regression analysis. In this comprehensive guide, we will work with the California Housing dataset to predict median house values. We will not only use this dataset to build a linear regression model but also explore various statistical and visualization tools provided by Python's scientific libraries.
Importing the Dataset and Printing Details
The following code imports the California Housing dataset using Scikit-learn's fetch_california_housing function, and then prints various details, including feature names, the first five rows of data, and the first five target values.

Understanding the California Housing Dataset
The California Housing dataset contains information collected from the 1990 California census. It's a great dataset for regression tasks and contains the following features:
MedInc: Median income in a block. The unit is tens of thousands of US Dollars (e.g., 8.3252 means $83,252).
HouseAge: Median age of a house within a block. This is measured in years.
AveRooms: Average number of rooms in houses within a block.
AveBedrms: Average number of bedrooms within a block. Like AveRooms, it is a continuous variable without a specific unit.
Population: Total population in a block. This is an absolute number and does not have specific units beyond count of people.
AveOccup: Average number of people living in a household within a block. It's a ratio and doesn't have specific units.
Latitude: Latitude of the block. Measured in degrees.
Longitude: Longitude of the block. Also measured in degrees.
target: The median house value in units of hundreds of thousands of US Dollars (e.g., a value of 4.526 means $452,600).
Libraries Used
We'll use the following libraries:
sklearn: For data handling and model splitting.
statsmodels: For statistical modeling.
matplotlib: For plotting and visualization.
seaborn: For advanced plotting.
numpy: For numerical operations.
scipy: For scientific computations.
Building and Evaluating a Linear Regression Model
This code snippet is concerned with building and evaluating a linear regression model on the dataset using the statsmodels library.
Importing Libraries: Necessary libraries are imported, including statsmodels for the linear regression model, scikit-learn for data fetching and splitting, and Matplotlib for plotting.
Fetching the Data: The California Housing dataset is fetched, and the features (X) and target (y) are assigned.
Adding Intercept: The sm.add_constant function is used to add a constant term to the features, allowing for an intercept in the linear regression model.
Splitting the Data: The dataset is divided into training and testing sets using the train_test_split function, with 80% of the data for training and 20% for testing.
Creating and Fitting the Model: A linear regression model (Ordinary Least Squares or OLS) is created with the training data, and the model is fit using the fit method.
Making Predictions: Predictions on the testing data are made using the predict method.
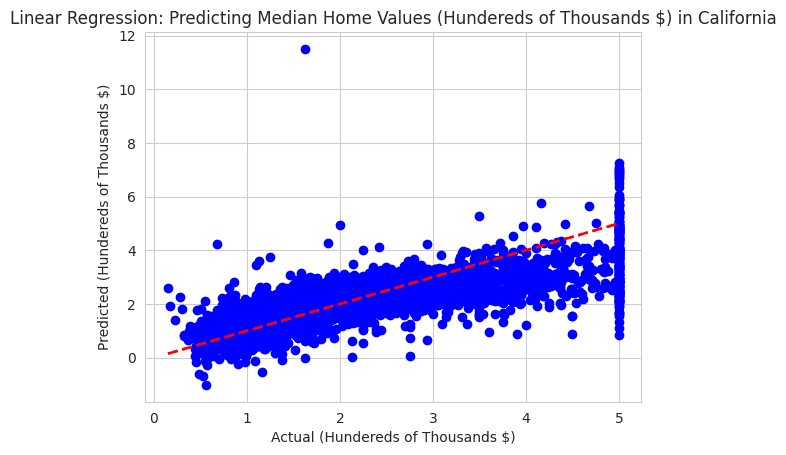
Plotting the Results: A scatter plot of the actual versus predicted values is created. The red dashed line represents a perfect prediction, where actual values would equal predicted values. The scatter plot helps in visually assessing how well the model's predictions align with the actual values.
Printing Summary: Finally, the summary of the regression results is printed using the summary method. The summary includes detailed statistics about the fit of the model, such as coefficients, standard errors, confidence intervals, R-squared values, etc., and custom feature names are provided by concatenating 'Intercept' with the feature names from the dataset.
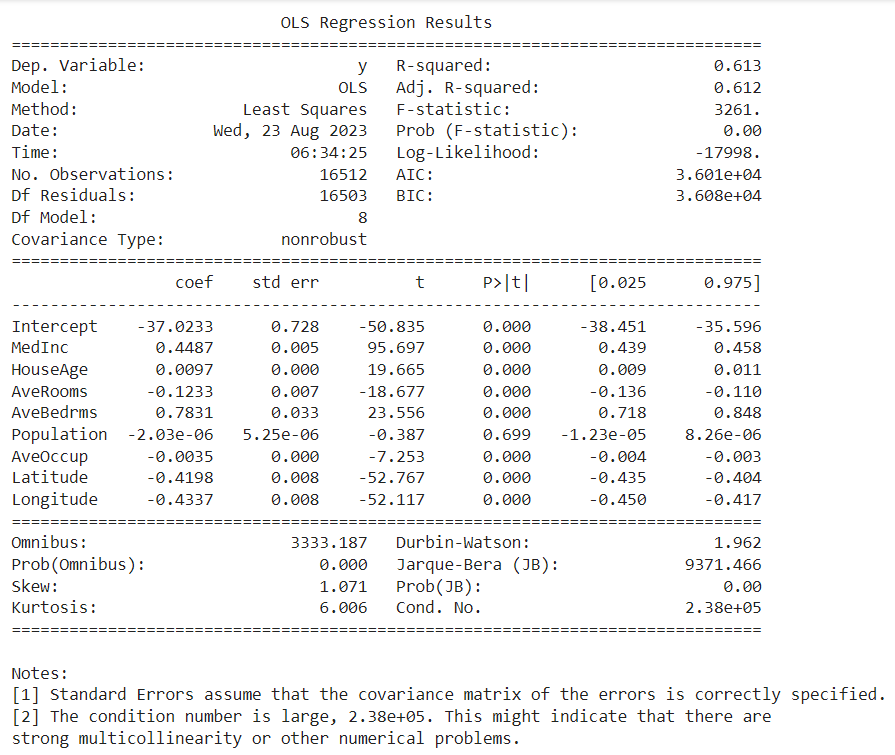
R-squared and Adjusted R-squared: The R-squared value of 0.613 indicates that 61.3% of the variability in the dependent variable can be explained by the model. The adjusted R-squared, which penalizes the addition of irrelevant features, is also 0.612, indicating a good balance between complexity and predictive power.
F-statistic and Prob (F-statistic): The F-statistic is 3261, and the corresponding probability is 0.00. This suggests that the model as a whole is statistically significant, and at least one of the predictors is relevant in predicting the dependent variable.
Coefficients:
Intercept: The intercept term is -37.0233, and it's significant at the 0.05 level, suggesting a substantial shift of the regression line from the origin.
MedInc: For every one-unit increase in Median Income, the dependent variable increases by 0.4487, holding all other variables constant.
HouseAge: A one-unit increase in House Age corresponds to an increase of 0.0097 in the dependent variable.
AveRooms and AveBedrms: These coefficients reflect the relationships with the average number of rooms and bedrooms.
Population: The coefficient is close to zero and has a high p-value (0.699), indicating that this variable might not be statistically significant.
AveOccup: Reflects the effect of average occupancy.
Latitude and Longitude: These coefficients may indicate spatial patterns in the data.
Omnibus and Prob(Omnibus): These statistics test the assumption of normally distributed residuals. A significant test (Prob(Omnibus) = 0.000) may suggest that the residuals are not normally distributed.
Durbin-Watson: A value of 1.962 is close to 2, indicating that there may be no first-order autocorrelation in the residuals.
Jarque-Bera (JB) and Prob(JB): Another test for normality of residuals, with a significant result indicating possible deviation from normality.
Kurtosis: The kurtosis of 6.006 could suggest that the residuals have heavier tails than a normal distribution.
Condition Number: The large condition number (2.38e+05) might indicate strong multicollinearity or other numerical problems. This may mean that some variables are highly correlated with each other, which can make the estimates less reliable.
In summary, the model seems to have good predictive power, but there might be some issues with multicollinearity. It would be advisable to investigate these aspects further, possibly considering variable transformations, diagnostics, or using regularization techniques.
Scatter Plots of Features vs Median House Value using Seaborn
This code is for visualizing the California Housing dataset by plotting scatter plots of its features against the target variable (median house value).
Imports: The necessary libraries, such as Seaborn (for visualization), Matplotlib (for plotting), and scikit-learn (for fetching the dataset), are imported.
Fetching the Data: The California Housing dataset is fetched using the fetch_california_housing function, containing features like housing median age, average rooms, etc., along with the target variable (median house value).
Styling and Palette Configuration: The sns.set_style function sets a modern grid background, and a palette is created with sns.color_palette to have different colors for each feature plot, making them easily distinguishable.
Figure and Axes Configuration: A grid of subplots is created with 2 rows and 4 columns using plt.subplots, and a shared y-axis (sharey=True). The figure size is also set to be 16 by 10 inches.
Plotting: A loop iterates over the features of the dataset, and for each feature, it determines the corresponding row and column in the grid to place the scatter plot. The sns.scatterplot function is used to create each scatter plot, and each subplot's title, x-label, and y-label are customized to represent the feature being plotted. The unique color for each feature comes from the previously defined palette, and alpha is set to 0.6 to make the points slightly transparent.
Final Adjustments: A main title for the entire figure is added using plt.suptitle, and plt.tight_layout is used to ensure that the subplots are spaced nicely without overlapping. Finally, the plt.show() function is called to render and display the plots.
Overall, the code effectively creates a visualization of the relationships between the features and target variable in the California Housing dataset, helping in understanding and interpreting patterns within the data.
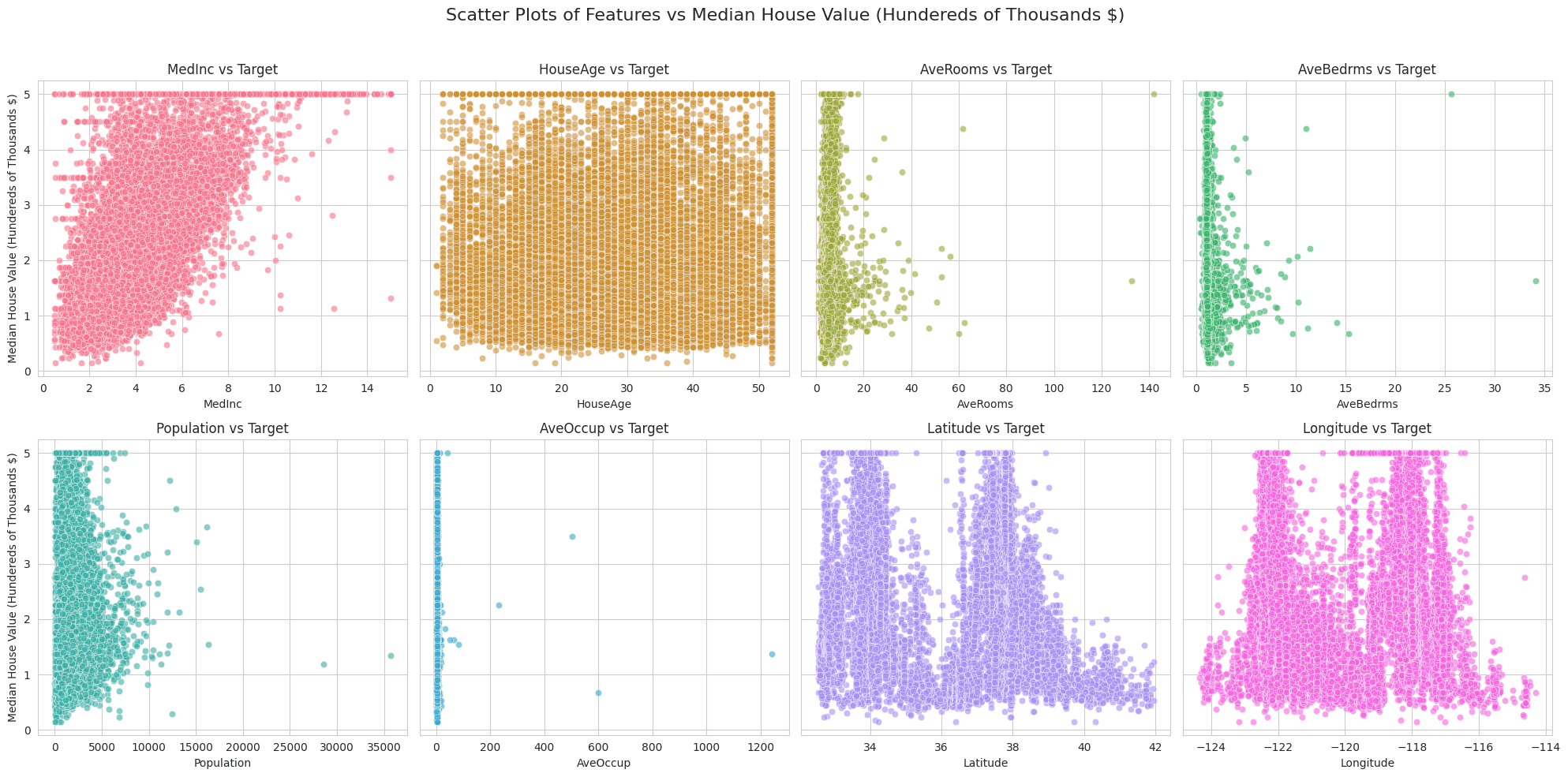
We can see some outliers in the data and linear patterns as well with target variable. Outliers are data points that are significantly different from most other data points. In the context of these scatter plots, outliers may be seen as points that lie far from the rest of the data. Outliers might indicate errors in data collection, unique or rare occurrences, or true variations. They can have significant effects on the results of statistical analyses and machine learning models, often leading to skewed results. We will remove these outliers from the data in the second round of analysis to compare the results.
Residuals Plot
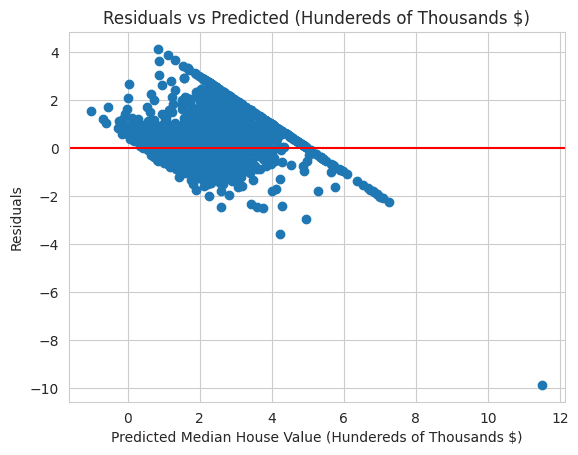
This code snippet is responsible for calculating and plotting the residuals of the predictions made by the linear regression model on the test data.
Calculating Residuals: Residuals are the differences between the actual values (y_test) and the predicted values (y_pred). These differences are calculated by simple subtraction and stored in the variable residuals.
Plotting the Residuals: A scatter plot is created to visualize the residuals against the predicted values. Each point on the plot represents a specific observation in the test data, with the x-coordinate being the predicted value and the y-coordinate being the corresponding residual.
Adding a Horizontal Line: The plt.axhline function is used to draw a horizontal line at y=0. This line serves as a reference, indicating where the residuals would be if the predictions were perfect (i.e., no difference between predicted and actual values).
Labeling the Axes and Title: Labels for the x and y-axes are added to denote what each axis represents, and a title is provided to summarize the plot.
Displaying the Plot: The plt.show() function is called to render and display the plot.
The resulting plot provides insight into the model's errors. Ideally, you would like to see a random scatter of points around the horizontal line at y=0, with no clear pattern or trend. Any noticeable pattern in the residuals might indicate that there's a systematic error in the predictions, possibly because a significant variable has been omitted, or the underlying relationship between the variables isn't truly linear. This plot is a crucial diagnostic tool for understanding the quality and limitations of the linear regression model.
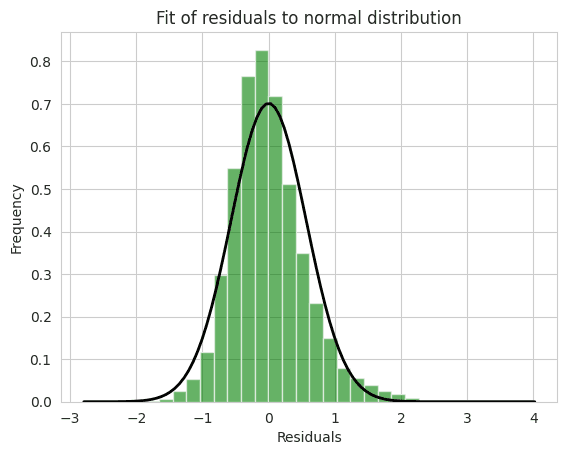
Distribution of Residuals
This code snippet is focused on analyzing the residuals from the previously fit linear regression model, specifically by examining their distribution and fitting them to a normal distribution.
Accessing Residuals: The residuals are accessed directly from the fitted model's results using results.resid.
Plotting Histogram of Residuals: A histogram of the residuals is created using plt.hist. The bins parameter is set to 30, dividing the residuals into 30 equal-width bins, and density=True ensures that the histogram is normalized, so it represents a probability density. The alpha value and color are set for styling.
Fitting a Normal Distribution: The norm.fit function from the SciPy library is used to fit a normal distribution to the residuals. The function returns the mean (mu) and standard deviation (std) of the fitted distribution.
Plotting the Normal Distribution Curve: A normal distribution curve is plotted over the histogram using the mean and standard deviation found in the previous step. The np.linspace function is used to create an array of x-values covering the range of the plot, and norm.pdf is used to calculate the corresponding probability density function (pdf) values. The line is plotted with a black color ('k') and a linewidth of 2.
Adding Labels and Title: Labels are added to the x and y-axes, and a title is set to describe the plot.
Displaying the Plot: Finally, plt.show() is called to render and display the plot.
The resulting plot provides a visual assessment of whether the residuals follow a normal distribution. In linear regression analysis, the normality of residuals is one of the key assumptions, and this plot can help in evaluating whether that assumption is met. If the residuals closely follow the normal distribution curve, it provides evidence that the assumption is reasonable for the given data and model. If not, it may indicate potential issues with the model or the data that may need to be addressed.

Remove outliers and rebuild Regression
This code snippet builds on the previous linear regression modeling of the California Housing dataset by adding a step to remove outliers from the data before modeling. Here's an overview of what the code does:
Reshaping Target Variable: The target variable y is reshaped into a two-dimensional array to align with the shape of the feature matrix X.
Combining Features and Target: Both the features and target are combined into one array called data_combined. This facilitates the outlier removal step as it allows for the simultaneous consideration of features and target.
Removing Outliers: Outliers are identified and removed using the 1.5 * IQR (Interquartile Range) rule. The 25th percentile (Q1) and 75th percentile (Q3) are calculated for each feature, and the interquartile range (IQR) is computed as Q3 - Q1. Observations falling outside the bounds defined by Q1 - 1.5 * IQR and Q3 + 1.5 * IQR are considered outliers and are removed from the dataset.
Splitting Filtered Data: The filtered data is split back into features (X_filtered) and target (y_filtered).
Adding Intercept: A constant term is added to the features for the linear regression model's intercept.
Splitting into Training and Testing Sets: The data is divided into training and testing sets using an 80-20 split, just like before.
Creating and Fitting the Model: A linear regression model is created and fit to the training data using the statsmodels library, exactly as in the previous code.
Making Predictions: Predictions are made on the testing data.
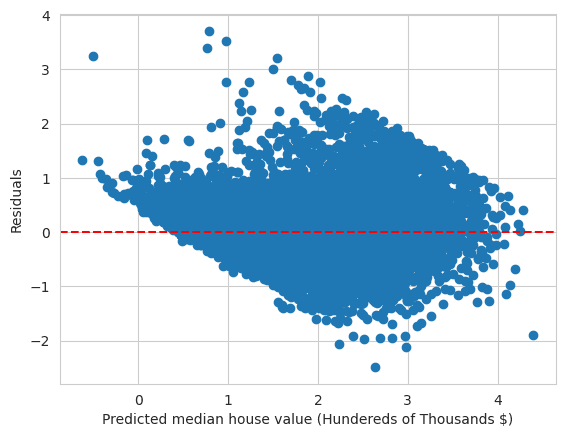
Plotting Actual vs. Predicted Values: A scatter plot is created to visualize the actual versus predicted values, similar to the earlier code, but with a modified title reflecting the removal of outliers.
Printing Summary Results: A summary of the regression results is printed, displaying various statistics related to the fit of the model.
The key difference in this code compared to the earlier version is the step of outlier removal, which can potentially lead to an improved model fit by removing extreme values that can unduly influence the model's parameters. This entire code snippet illustrates the process of robust linear regression modeling by integrating data preprocessing, model fitting, visualization, and statistical evaluation, with a focus on handling outliers.

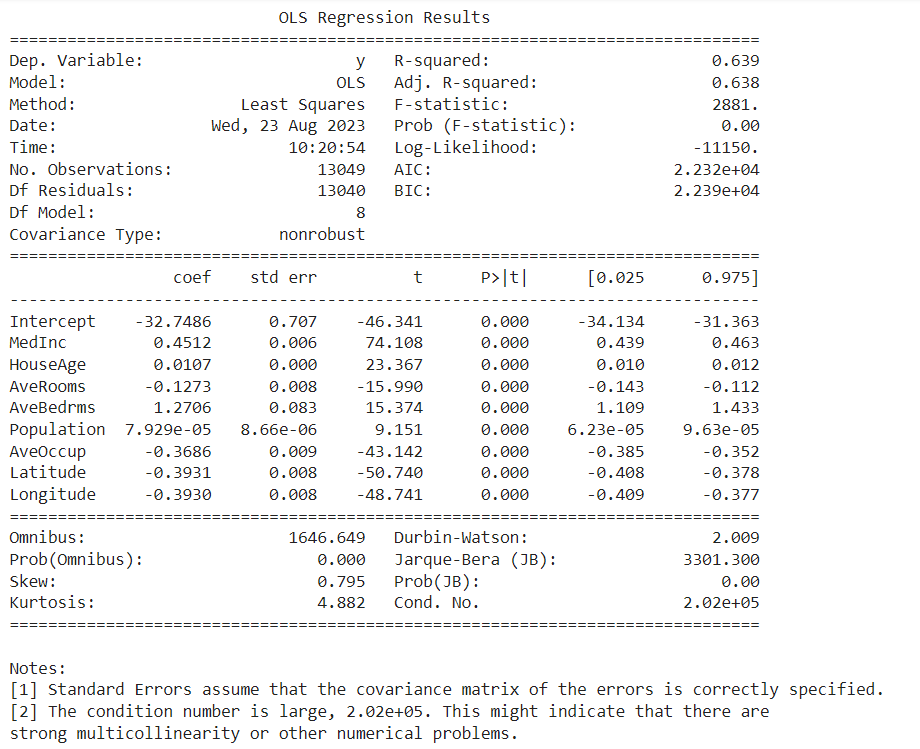
R-squared and Adjusted R-squared: The R-squared value has increased to 0.639, indicating that 63.9% of the variability in the dependent variable can be explained by the model. This indicates a better fit compared to the previous model.
F-statistic and Prob (F-statistic): The F-statistic is 2881, with a p-value of 0.00, confirming that the model is statistically significant.
Coefficients:
Intercept: The intercept is -32.7486, showing a significant shift from the origin.
MedInc: A one-unit increase in Median Income corresponds to an increase of 0.4512 in the dependent variable.
HouseAge: A slight increase in the coefficient compared to the previous model.
AveRooms and AveBedrms: Similar relationships, with a noticeable increase in the coefficient for AveBedrms.
Population: Now a significant predictor with a coefficient of 7.929e-05.
AveOccup: A large negative coefficient indicates a significant relationship between average occupancy and the dependent variable.
Latitude and Longitude: Similar spatial effects as in the previous model.
Omnibus and Prob(Omnibus): These statistics remain significant, indicating possible deviation from normality in the residuals.
Durbin-Watson: The value of 2.009 is even closer to 2, suggesting no autocorrelation in the residuals.
Jarque-Bera (JB) and Prob(JB): These confirm the non-normality of residuals.
Kurtosis: The kurtosis has decreased to 4.882, though it might still suggest some non-normality in the residuals.
Condition Number: Still large at 2.02e+05, indicating that there might be strong multicollinearity or other numerical problems.
In summary, this model shows improvement over the previous one, especially in the R-squared value and the significance of some predictors. However, the concerns regarding multicollinearity and non-normality in the residuals remain, and further investigation might be required. The noticeable changes in coefficients (such as AveBedrms and Population) could indicate the impact of data transformation, preprocessing steps, or different subsets of data used for this model.
Scatter Plots of Features vs Median House Value (Outliers Removed)

The Fit of Residual to Normal Distribution
Residual Plot (Outliers Removed)
Summary
Model 1 and Model 2 are linear regression models developed to predict median home values in California. Model 1 has an R-squared value of 0.613, explaining 61.3% of the variability in the data, and has one insignificant predictor, Population. However, Model 2, which includes transformations and removal of outliers, improved the R-squared to 0.639. The significant predictors in Model 1 remained significant in Model 2, and Population became significant as well. Notably, there were changes in coefficients, such as a substantial increase in the coefficient of AveBedrms in Model 2. Our exploration of the California housing market through regression analysis has uncovered valuable insights into the various factors that drive housing prices in the region. By methodically removing outliers and analyzing the relationships between features such as median income, house age, average rooms, and geographical coordinates, we've crafted a predictive model that mirrors the subtleties of the housing landscape. This study highlights the intricate interplay of socio-economic and geographical factors that influence housing prices and underscores the importance of data-driven decision-making in real estate. The findings not only provide homebuyers, investors, and policymakers with a quantitative lens to view the housing market but also stress the need for continual adaptation and validation in response to changing market dynamics. Our journey through California's diverse housing terrain reveals a compelling story, one that beckons further exploration and application, potentially revolutionizing the way we understand and engage with real estate.
The full working code for the examples above can be found in the PyFi GitHub Repo.
Written by Numan Yaqoob, PHD candidate