This article walks you through stock price prediction using Machine Learning models built with Python. Our specific focus will be on forecasting Apple Inc. (AAPL) stock price by applying different machine learning models to historical stock data. When you’re done, you’ll have access to all of the code used here, and will be able to plug this in to your work. Let's take a closer look at the code and walk through the step-by-step process involved.

Data Pre-processing
First, we need to load the stock data from a CSV file. We will be using the 'AAPL_short_volume.csv' file from OpenBB, a leading open-source investment analysis company, which contains the closing prices of AAPL stock. The data will be stored in a Pandas Data Frame, and we will extract the 'Close' column for further processing.
import pandas as pd # Load the stock data file_path = 'https://openbb.co/AAPL_short_volume.csv' data = pd.read_csv(file_path) close_prices_AAPL = data['Close']
import pandas as pd # Load the stock data file_path = 'https://openbb.co/AAPL_short_volume.csv' data = pd.read_csv(file_path) close_prices_AAPL = data['Close']
import pandas as pd # Load the stock data file_path = 'https://openbb.co/AAPL_short_volume.csv' data = pd.read_csv(file_path) close_prices_AAPL = data['Close']
After importing the historical stock data, the next step is to plot a line graph of the time series data.
# Create the line plot plt.figure(figsize=(12, 6)) # Set the figure size # Plot the time series data plt.plot(close_prices_AAPL_reverse) # Customize the plot plt.title('AAPL Stock Prices') # Set the title plt.xlabel('Time') # Set the x-axis label plt.ylabel('Stock Price') # Set the y-axis label # Display the plot plt.show() # Create the line plot plt.figure(figsize=(12, 6)) # Set the figure size # Plot the time series data plt.plot(close_prices_AAPL_reverse) # Customize the plot plt.title('AAPL Stock Prices') # Set the title plt.xlabel('Time') # Set the x-axis label plt.ylabel('Stock Price') # Set the y-axis label # Display the plot plt.show() # Create the line plot plt.figure(figsize=(12, 6)) # Set the figure size # Plot the time series data plt.plot(close_prices_AAPL_reverse) # Customize the plot plt.title('AAPL Stock Prices') # Set the title plt.xlabel('Time') # Set the x-axis label plt.ylabel('Stock Price') # Set the y-axis label # Display the plot plt.show()
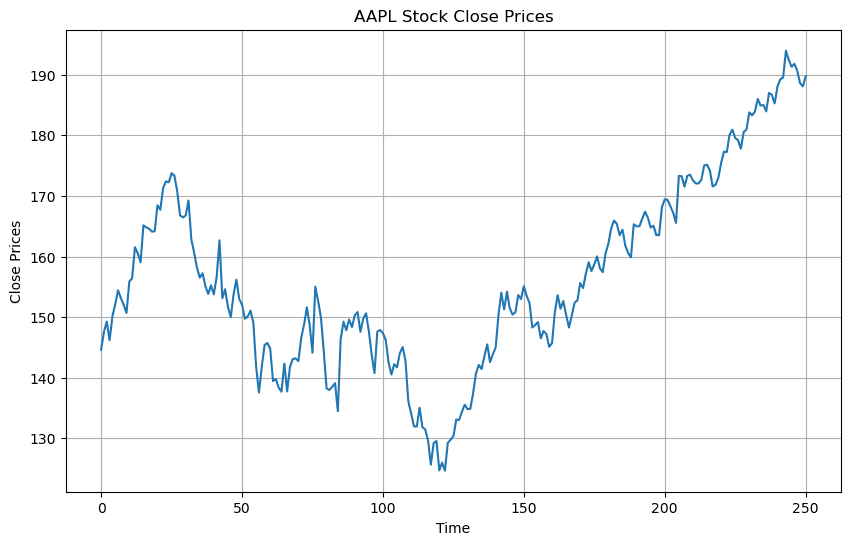
Once we have our graph, we will move onto some data pre-processing steps. This is necessary because it is essential for improving data quality and handling missing values and outliers.It involves normalization to bring features to a common scale, pre-processing enhances model performance and ensures data compatibility with analysis techniques. Here we are reshaping the data to have a single feature and normalize it to the range [0, 1]. This normalization step is essential to ensure that all features have the same scale and to improve the model's convergence. Before Data processing Numpy is imported in Python for its efficient numerical computing capabilities. It provides N-dimensional arrays for handling large datasets and a wide range of mathematical functions for array operation.
import numpy as np # Data preprocessing data = close_prices_AAPL_reverse.values.reshape(-1, 1) # Reshape the data data_normalized = data / np.max(data) # Normalize the data
import numpy as np # Data preprocessing data = close_prices_AAPL_reverse.values.reshape(-1, 1) # Reshape the data data_normalized = data / np.max(data) # Normalize the data
import numpy as np # Data preprocessing data = close_prices_AAPL_reverse.values.reshape(-1, 1) # Reshape the data data_normalized = data / np.max(data) # Normalize the data
We will split the data into training and testing sets. Here, we assign 80% of the data for training and the remaining 20% for testing. The training data will be used to train our models, while the testing data will be used to evaluate their performance. Train data is used to learn patterns and features and test data is used to evaluate models performance on unseen data. This ensures the models' generalization capability.
# Split the data into training and testing sets train_size = int(len(data_normalized) * 0.8) train_data = data_normalized[:train_size] test_data = data_normalized[train_size:]
# Split the data into training and testing sets train_size = int(len(data_normalized) * 0.8) train_data = data_normalized[:train_size] test_data = data_normalized[train_size:]
# Split the data into training and testing sets train_size = int(len(data_normalized) * 0.8) train_data = data_normalized[:train_size] test_data = data_normalized[train_size:]
LSTM Model
We will start with a Long Short-Term Memory (LSTM) model, which is a type of recurrent neural network (RNN) suitable for sequential data like stock prices. LSTM models are known for their ability to capture temporal dependencies and make accurate predictions. In this code TensorFlow is an open-source deep learning library developed by Google. It allows you to build and train various machine learning and deep learning models efficiently using neural networks.
Sequential is a class in tensor flow’s Keras API that allows you to create a linear stack of layers in a neural network. Dense is a layer type in TensorFlow used for fully connected layers in neural networks, where every neuron is connected to every neuron in the previous and next layer. Dropout is a regularization technique used to prevent overfitting in neural networks. It randomly sets a fraction of input units to zero during the training, which helps in reducing the co-adaptation of neurons and improves the generalization of the model. Adam is an optimization algorithm used for training neural networks. It is an adaptive learning rate optimization algorithm that combines the benefits of AdaGrad and RMSprop. It dynamically adjusts the learning rates for each parameter, making it well suited for a wide range of deep learning tasks.
from tensorflow.keras.models import Sequential from tensorflow.keras.layers import LSTM, Dense, Dropout from tensorflow.keras.optimizers import Adam # Function to create LSTM model def create_lstm_model(units, activation, learning_rate): model = Sequential() model.add(LSTM(units=units, activation=activation, input_shape=(1, 1))) model.add(Dense(units=1)) optimizer = Adam(learning_rate=learning_rate) model.compile(optimizer=optimizer, loss='mean_squared_error') return model
from tensorflow.keras.models import Sequential from tensorflow.keras.layers import LSTM, Dense, Dropout from tensorflow.keras.optimizers import Adam # Function to create LSTM model def create_lstm_model(units, activation, learning_rate): model = Sequential() model.add(LSTM(units=units, activation=activation, input_shape=(1, 1))) model.add(Dense(units=1)) optimizer = Adam(learning_rate=learning_rate) model.compile(optimizer=optimizer, loss='mean_squared_error') return model
from tensorflow.keras.models import Sequential from tensorflow.keras.layers import LSTM, Dense, Dropout from tensorflow.keras.optimizers import Adam # Function to create LSTM model def create_lstm_model(units, activation, learning_rate): model = Sequential() model.add(LSTM(units=units, activation=activation, input_shape=(1, 1))) model.add(Dense(units=1)) optimizer = Adam(learning_rate=learning_rate) model.compile(optimizer=optimizer, loss='mean_squared_error') return model
We define a function, create_lstm_model, to create the LSTM model with the given hyperparameters. The function takes the number of LSTM units, activation function, and learning rate as inputs. The model consists of an LSTM layer followed by a dense output layer. We use the Adam optimizer and mean squared error loss for training the model.
Next, we define a set of hyperparameters for tuning the LSTM model. We specify different values for the number of LSTM units, activation functions, and learning rates. We will perform a grid search to find the best combination of hyperparameters.
# Define hyperparameters for tuning lstm_units = [50, 100, 200] lstm_activations = ['relu', 'tanh'] learning_rates = [0.001, 0.01, 0.1] epochs = 100 batch_size = 32
# Define hyperparameters for tuning lstm_units = [50, 100, 200] lstm_activations = ['relu', 'tanh'] learning_rates = [0.001, 0.01, 0.1] epochs = 100 batch_size = 32
# Define hyperparameters for tuning lstm_units = [50, 100, 200] lstm_activations = ['relu', 'tanh'] learning_rates = [0.001, 0.01, 0.1] epochs = 100 batch_size = 32
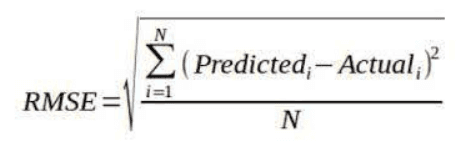
We initialize a variable, best_rmse, with a high value to keep track of the best root mean squared error (RMSE) achieved by the LSTM model. Root Mean Square Error is calculated with the following formula -
We will update this value as we find better models during the grid search.
# Perform hyperparameter tuning for LSTM model best_rmse = float('inf') best_lstm_model = None # Perform hyperparameter tuning for LSTM model best_rmse = float('inf') best_lstm_model = None # Perform hyperparameter tuning for LSTM model best_rmse = float('inf') best_lstm_model = NoneNow, we iterate over all possible combinations of hyperparameters and train the LSTM models. For each combination, we create the LSTM model, train it on the training data, and make predictions on the testing data. We calculate the RMSE between the actual and predicted values and update the best_rmse and best_lstm_model variables if we find a model with a lower RMSE.
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_squared_error
for units in lstm_units: for activation in lstm_activations: for learning_rate in learning_rates: # Create and train LSTM model model = create_lstm_model(units=units, activation=activation, learning_rate=learning_rate) model.fit(train_data[:-1].reshape(-1, 1, 1), train_data[1:], epochs=epochs, batch_size=batch_size, verbose=0) # Predict on test data test_predictions = model.predict(test_data[:-1].reshape(-1, 1, 1)).flatten() # Calculate RMSE rmse = np.sqrt(mean_squared_error(test_data[1:], test_predictions)) # Check if current model has lower RMSE if rmse < best_rmse: best_rmse = rmse best_lstm_model = model
for units in lstm_units: for activation in lstm_activations: for learning_rate in learning_rates: # Create and train LSTM model model = create_lstm_model(units=units, activation=activation, learning_rate=learning_rate) model.fit(train_data[:-1].reshape(-1, 1, 1), train_data[1:], epochs=epochs, batch_size=batch_size, verbose=0) # Predict on test data test_predictions = model.predict(test_data[:-1].reshape(-1, 1, 1)).flatten() # Calculate RMSE rmse = np.sqrt(mean_squared_error(test_data[1:], test_predictions)) # Check if current model has lower RMSE if rmse < best_rmse: best_rmse = rmse best_lstm_model = model
for units in lstm_units: for activation in lstm_activations: for learning_rate in learning_rates: # Create and train LSTM model model = create_lstm_model(units=units, activation=activation, learning_rate=learning_rate) model.fit(train_data[:-1].reshape(-1, 1, 1), train_data[1:], epochs=epochs, batch_size=batch_size, verbose=0) # Predict on test data test_predictions = model.predict(test_data[:-1].reshape(-1, 1, 1)).flatten() # Calculate RMSE rmse = np.sqrt(mean_squared_error(test_data[1:], test_predictions)) # Check if current model has lower RMSE if rmse < best_rmse: best_rmse = rmse best_lstm_model = model
After finding the best LSTM model, we make predictions on the entire dataset and inverse normalize the predictions to obtain the actual stock prices.
# Predict on the entire dataset using the best LSTM model all_lstm_predictions = best_lstm_model.predict(data_normalized[:-1].reshape(-1, 1, 1)).flatten() # Inverse normalize the LSTM predictions all_lstm_predictions = all_lstm_predictions * np.max(data)
# Predict on the entire dataset using the best LSTM model all_lstm_predictions = best_lstm_model.predict(data_normalized[:-1].reshape(-1, 1, 1)).flatten() # Inverse normalize the LSTM predictions all_lstm_predictions = all_lstm_predictions * np.max(data)
# Predict on the entire dataset using the best LSTM model all_lstm_predictions = best_lstm_model.predict(data_normalized[:-1].reshape(-1, 1, 1)).flatten() # Inverse normalize the LSTM predictions all_lstm_predictions = all_lstm_predictions * np.max(data)
Support Vector Machines (SVM) Model
We will now explore Support Vector Machines (SVM). SVM is a popular non-linear regression model that finds the best hyperplane to separate the data points.
from sklearn.svm import SVR from sklearn.model_selection import GridSearchCV # Support Vector Machines (SVM) Model svm_model = SVR() svm_params = { 'C': [0.1, 1, 10], 'gamma': [0.01, 0.1, 1] } svm_grid_search = GridSearchCV(svm_model, svm_params, scoring='neg_mean_squared_error') svm_grid_search.fit(np.arange(len(close_prices_AAPL_reverse)).reshape(-1, 1), close_prices_AAPL_reverse) svm_best_model = svm_grid_search.best_estimator_ svm_predictions = svm_best_model.predict(np.arange(len(close_prices_AAPL_reverse)).reshape(-1, 1)) from sklearn.svm import SVR from sklearn.model_selection import GridSearchCV # Support Vector Machines (SVM) Model svm_model = SVR() svm_params = { 'C': [0.1, 1, 10], 'gamma': [0.01, 0.1, 1] } svm_grid_search = GridSearchCV(svm_model, svm_params, scoring='neg_mean_squared_error') svm_grid_search.fit(np.arange(len(close_prices_AAPL_reverse)).reshape(-1, 1), close_prices_AAPL_reverse) svm_best_model = svm_grid_search.best_estimator_ svm_predictions = svm_best_model.predict(np.arange(len(close_prices_AAPL_reverse)).reshape(-1, 1)) from sklearn.svm import SVR from sklearn.model_selection import GridSearchCV # Support Vector Machines (SVM) Model svm_model = SVR() svm_params = { 'C': [0.1, 1, 10], 'gamma': [0.01, 0.1, 1] } svm_grid_search = GridSearchCV(svm_model, svm_params, scoring='neg_mean_squared_error') svm_grid_search.fit(np.arange(len(close_prices_AAPL_reverse)).reshape(-1, 1), close_prices_AAPL_reverse) svm_best_model = svm_grid_search.best_estimator_ svm_predictions = svm_best_model.predict(np.arange(len(close_prices_AAPL_reverse)).reshape(-1, 1)) We initialize an SVM model and define a set of hyperparameters to tune using a grid search. The grid search selects the best hyperparameters based on the negative mean squared error scoring. We fit the SVM model to the data and make predictions on the entire dataset.
Random Forest Model
Next, we explore the Random Forest model, which is an ensemble model consisting of multiple decision trees. Random Forest models are known for their robustness and ability to handle complex relationships in the data.
from sklearn.ensemble import RandomForestRegressor # Random Forest Model rf_model = RandomForestRegressor() rf_params = { 'n_estimators': [50, 100, 200], 'max_depth': [None, 5, 10] } rf_grid_search = GridSearchCV(rf_model, rf_params, scoring='neg_mean_squared_error') rf_grid_search.fit(np.arange(len(close_prices_AAPL_reverse)).reshape(-1, 1), close_prices_AAPL_reverse) from sklearn.ensemble import RandomForestRegressor # Random Forest Model rf_model = RandomForestRegressor() rf_params = { 'n_estimators': [50, 100, 200], 'max_depth': [None, 5, 10] } rf_grid_search = GridSearchCV(rf_model, rf_params, scoring='neg_mean_squared_error') rf_grid_search.fit(np.arange(len(close_prices_AAPL_reverse)).reshape(-1, 1), close_prices_AAPL_reverse) from sklearn.ensemble import RandomForestRegressor # Random Forest Model rf_model = RandomForestRegressor() rf_params = { 'n_estimators': [50, 100, 200], 'max_depth': [None, 5, 10] } rf_grid_search = GridSearchCV(rf_model, rf_params, scoring='neg_mean_squared_error') rf_grid_search.fit(np.arange(len(close_prices_AAPL_reverse)).reshape(-1, 1), close_prices_AAPL_reverse)We initialize a Random Forest model and define a set of hyperparameters for tuning. Similar to the SVM model, we use a grid search to find the best combination of hyperparameters based on the negative mean squared error. We fit the Random Forest model to the data and make predictions on the entire dataset.
Gradient Boosting Methods (XGBoost and LightGBM)
Lastly, we explore two popular gradient boosting methods, XGBoost and LightGBM. These models are known for their efficiency and excellent performance in many machine learning tasks.
from xgboost import XGBRegressor from lightgbm import LGBMRegressor # Gradient Boosting Methods (XGBoost) xgb_model = XGBRegressor() xgb_params = { 'learning_rate': [0.1, 0.01, 0.001], 'max_depth': [3, 5, 7] } xgb_grid_search = GridSearchCV(xgb_model, xgb_params, scoring='neg_mean_squared_error') xgb_grid_search.fit(np.arange(len(close_prices_AAPL_reverse)).reshape(-1, 1), close_prices_AAPL_reverse) xgb_best_model = xgb_grid_search.best_estimator_ xgb_predictions = xgb_best_model.predict(np.arange(len(close_prices_AAPL)).reshape(-1, 1)) # Gradient Boosting Methods (LightGBM) lgbm_model = LGBMRegressor() lgbm_params = { 'learning_rate': [0.1, 0.01, 0.001], 'max_depth': [3, 5, 7] } from xgboost import XGBRegressor from lightgbm import LGBMRegressor # Gradient Boosting Methods (XGBoost) xgb_model = XGBRegressor() xgb_params = { 'learning_rate': [0.1, 0.01, 0.001], 'max_depth': [3, 5, 7] } xgb_grid_search = GridSearchCV(xgb_model, xgb_params, scoring='neg_mean_squared_error') xgb_grid_search.fit(np.arange(len(close_prices_AAPL_reverse)).reshape(-1, 1), close_prices_AAPL_reverse) xgb_best_model = xgb_grid_search.best_estimator_ xgb_predictions = xgb_best_model.predict(np.arange(len(close_prices_AAPL)).reshape(-1, 1)) # Gradient Boosting Methods (LightGBM) lgbm_model = LGBMRegressor() lgbm_params = { 'learning_rate': [0.1, 0.01, 0.001], 'max_depth': [3, 5, 7] } from xgboost import XGBRegressor from lightgbm import LGBMRegressor # Gradient Boosting Methods (XGBoost) xgb_model = XGBRegressor() xgb_params = { 'learning_rate': [0.1, 0.01, 0.001], 'max_depth': [3, 5, 7] } xgb_grid_search = GridSearchCV(xgb_model, xgb_params, scoring='neg_mean_squared_error') xgb_grid_search.fit(np.arange(len(close_prices_AAPL_reverse)).reshape(-1, 1), close_prices_AAPL_reverse) xgb_best_model = xgb_grid_search.best_estimator_ xgb_predictions = xgb_best_model.predict(np.arange(len(close_prices_AAPL)).reshape(-1, 1)) # Gradient Boosting Methods (LightGBM) lgbm_model = LGBMRegressor() lgbm_params = { 'learning_rate': [0.1, 0.01, 0.001], 'max_depth': [3, 5, 7] }We follow a similar approach for both XGBoost and LightGBM models. We initialize the models and define a set of hyperparameters for tuning using a grid search. We fit the models to the data and make predictions on the entire dataset.
Model Evaluation and Visualization
To evaluate the models' performance, we calculate the root mean squared error (RMSE) between the actual and predicted stock prices. Lower RMSE values indicate better model performance. We plot the actual and predicted values for each model to visualize their predictions.
import matplotlib.pyplot as plt from sklearn.metrics import mean_squared_error # Function to calculate RMSE def rmse(y_true, y_pred): return np.sqrt(mean_squared_error(y_true, y_pred)) # List of model names and predictions model_names = ['Support Vector Machines (SVM)', 'Random Forest', 'XGBoost', 'LightGBM'] predictions = [svm_predictions, rf_predictions, xgb_predictions, lgbm_predictions] best_models = [svm_best_model, rf_best_model, xgb_best_model, lgbm_best_model] # Truncate actual values to match the length of predictions actual_values = close_prices_AAPL_reverse[-len(svm_predictions):] # Evaluate models and plot graphs for i, model_name in enumerate(model_names): model_prediction = predictions[i] model_prediction_truncated = model_prediction[-len(actual_values):] # Truncate predicted values model_rmse = rmse(actual_values, model_prediction_truncated) # Plotting actual and predicted values plt.figure(figsize=(8, 6)) plt.plot(actual_values, label='Actual') plt.plot(model_prediction, label='Predicted') plt.title(f"{model_name} - RMSE: {model_rmse:.2f}") plt.xlabel('Time') plt.ylabel('Stock Price') plt.legend() plt.show() # Print the best hyperparameters for the model best_model = best_models[i] print(f"Best Hyperparameters for {model_name}:") print(best_model) print("-----------------------------") import matplotlib.pyplot as plt from sklearn.metrics import mean_squared_error # Function to calculate RMSE def rmse(y_true, y_pred): return np.sqrt(mean_squared_error(y_true, y_pred)) # List of model names and predictions model_names = ['Support Vector Machines (SVM)', 'Random Forest', 'XGBoost', 'LightGBM'] predictions = [svm_predictions, rf_predictions, xgb_predictions, lgbm_predictions] best_models = [svm_best_model, rf_best_model, xgb_best_model, lgbm_best_model] # Truncate actual values to match the length of predictions actual_values = close_prices_AAPL_reverse[-len(svm_predictions):] # Evaluate models and plot graphs for i, model_name in enumerate(model_names): model_prediction = predictions[i] model_prediction_truncated = model_prediction[-len(actual_values):] # Truncate predicted values model_rmse = rmse(actual_values, model_prediction_truncated) # Plotting actual and predicted values plt.figure(figsize=(8, 6)) plt.plot(actual_values, label='Actual') plt.plot(model_prediction, label='Predicted') plt.title(f"{model_name} - RMSE: {model_rmse:.2f}") plt.xlabel('Time') plt.ylabel('Stock Price') plt.legend() plt.show() # Print the best hyperparameters for the model best_model = best_models[i] print(f"Best Hyperparameters for {model_name}:") print(best_model) print("-----------------------------") import matplotlib.pyplot as plt from sklearn.metrics import mean_squared_error # Function to calculate RMSE def rmse(y_true, y_pred): return np.sqrt(mean_squared_error(y_true, y_pred)) # List of model names and predictions model_names = ['Support Vector Machines (SVM)', 'Random Forest', 'XGBoost', 'LightGBM'] predictions = [svm_predictions, rf_predictions, xgb_predictions, lgbm_predictions] best_models = [svm_best_model, rf_best_model, xgb_best_model, lgbm_best_model] # Truncate actual values to match the length of predictions actual_values = close_prices_AAPL_reverse[-len(svm_predictions):] # Evaluate models and plot graphs for i, model_name in enumerate(model_names): model_prediction = predictions[i] model_prediction_truncated = model_prediction[-len(actual_values):] # Truncate predicted values model_rmse = rmse(actual_values, model_prediction_truncated) # Plotting actual and predicted values plt.figure(figsize=(8, 6)) plt.plot(actual_values, label='Actual') plt.plot(model_prediction, label='Predicted') plt.title(f"{model_name} - RMSE: {model_rmse:.2f}") plt.xlabel('Time') plt.ylabel('Stock Price') plt.legend() plt.show() # Print the best hyperparameters for the model best_model = best_models[i] print(f"Best Hyperparameters for {model_name}:") print(best_model) print("-----------------------------")
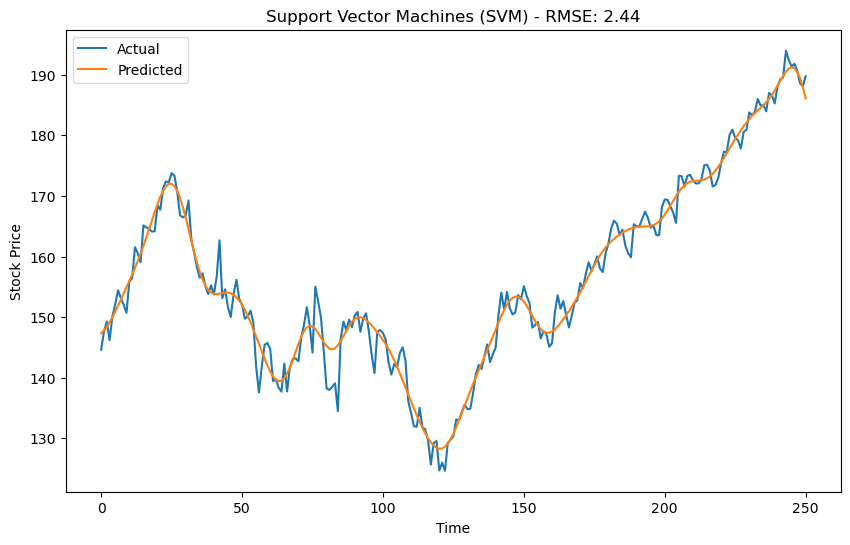
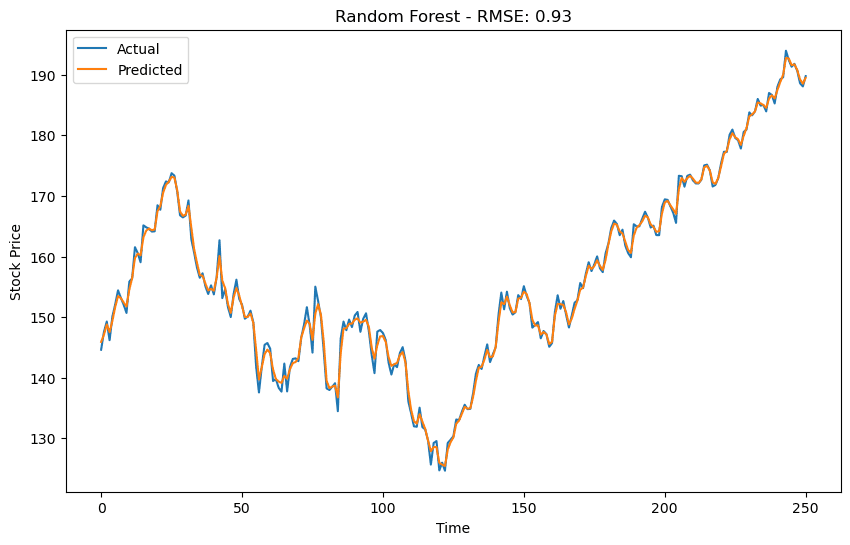


Finally, we plot the predictions made by the best LSTM model alongside the actual stock prices.
# Plotting LSTM predictions plt.figure(figsize=(10, 6)) plt.plot(close_prices_AAPL, label='Actual') plt.plot(all_lstm_predictions, label='LSTM Predicted') plt.title(f"LSTM Model - RMSE: {best_rmse:.2f}") plt.xlabel('Time') plt.ylabel('Stock Price') plt.legend() plt.show() # Plotting LSTM predictions plt.figure(figsize=(10, 6)) plt.plot(close_prices_AAPL, label='Actual') plt.plot(all_lstm_predictions, label='LSTM Predicted') plt.title(f"LSTM Model - RMSE: {best_rmse:.2f}") plt.xlabel('Time') plt.ylabel('Stock Price') plt.legend() plt.show() # Plotting LSTM predictions plt.figure(figsize=(10, 6)) plt.plot(close_prices_AAPL, label='Actual') plt.plot(all_lstm_predictions, label='LSTM Predicted') plt.title(f"LSTM Model - RMSE: {best_rmse:.2f}") plt.xlabel('Time') plt.ylabel('Stock Price') plt.legend() plt.show()

So far, we have explored various machine-learning models for predicting stock prices. We started with an LSTM model to capture temporal dependencies in the data. Then, we explored other models like Support Vector Machines, Random Forest, XGBoost, and LightGBM. We evaluated their performance using the root mean squared error (RMSE) metric and visualized the predictions. The LSTM model demonstrates superior predictive performance, exhibiting the lowest Root Mean Square Error (RMSE) among all the models. This highlights the strength and effectiveness of the LSTM model in forecasting stock prices accurately.
Future Forecasting using LSTM
Next, we will do forecast using LSTM Model.
# Prepare the data data = close_prices_AAPL_reverse.values.reshape(-1, 1) # Reshape the data data_normalized = data / np.max(data) # Normalize the data # Train the LSTM model model = best_lstm_model model.fit(train_data[:-1].reshape(-1, 1, 1), train_data[1:], epochs=epochs, batch_size=batch_size, verbose=0) # Generate future predictions future_data = np.copy(data_normalized[-1]) # Start with the last available data point future_predictions = [] # List to store the predicted values for _ in range(10): # Reshape the data for prediction input_data = future_data.reshape(1, 1, 1) # Make the prediction prediction = model.predict(input_data)[0][0] # Append the prediction to the list future_predictions.append(prediction) # Update the input data for the next prediction future_data = np.array([[prediction]]) # Inverse normalize the predictions future_predictions = np.array(future_predictions) * np.max(data) # Print the predicted values for the next 10 days print("Predicted Stock Prices for the Next 10 Days:") for i, prediction in enumerate(future_predictions, 1): print(f"Day {i}: {prediction:.2f}") # Prepare the data data = close_prices_AAPL_reverse.values.reshape(-1, 1) # Reshape the data data_normalized = data / np.max(data) # Normalize the data # Train the LSTM model model = best_lstm_model model.fit(train_data[:-1].reshape(-1, 1, 1), train_data[1:], epochs=epochs, batch_size=batch_size, verbose=0) # Generate future predictions future_data = np.copy(data_normalized[-1]) # Start with the last available data point future_predictions = [] # List to store the predicted values for _ in range(10): # Reshape the data for prediction input_data = future_data.reshape(1, 1, 1) # Make the prediction prediction = model.predict(input_data)[0][0] # Append the prediction to the list future_predictions.append(prediction) # Update the input data for the next prediction future_data = np.array([[prediction]]) # Inverse normalize the predictions future_predictions = np.array(future_predictions) * np.max(data) # Print the predicted values for the next 10 days print("Predicted Stock Prices for the Next 10 Days:") for i, prediction in enumerate(future_predictions, 1): print(f"Day {i}: {prediction:.2f}") # Prepare the data data = close_prices_AAPL_reverse.values.reshape(-1, 1) # Reshape the data data_normalized = data / np.max(data) # Normalize the data # Train the LSTM model model = best_lstm_model model.fit(train_data[:-1].reshape(-1, 1, 1), train_data[1:], epochs=epochs, batch_size=batch_size, verbose=0) # Generate future predictions future_data = np.copy(data_normalized[-1]) # Start with the last available data point future_predictions = [] # List to store the predicted values for _ in range(10): # Reshape the data for prediction input_data = future_data.reshape(1, 1, 1) # Make the prediction prediction = model.predict(input_data)[0][0] # Append the prediction to the list future_predictions.append(prediction) # Update the input data for the next prediction future_data = np.array([[prediction]]) # Inverse normalize the predictions future_predictions = np.array(future_predictions) * np.max(data) # Print the predicted values for the next 10 days print("Predicted Stock Prices for the Next 10 Days:") for i, prediction in enumerate(future_predictions, 1): print(f"Day {i}: {prediction:.2f}")

Conclusion
Each model has its strengths and weaknesses, and the choice of the best model depends on the specific problem and dataset. It is always a good practice to tune the hyperparameters of the models using techniques like grid search to achieve the best performance.
Remember that stock price prediction is a complex task influenced by various factors, and models may not always provide accurate predictions. It is crucial to consider other factors like market trends, news, and fundamental analysis while making investment decisions.
I hope you found this blog post informative and gained insights into predicting stock prices using machine learning models. Happy modeling and investing!
The complete code and data sets for this project can be found on the PyFi GitHub page.
Pull the code, try plugging in a different stocks historical data, and see what happens for yourself!
Written by Numan Yaqoob, PHD candidate
DISCLAIMER*This information is for educational purposes only, and is not financial advice. Trading securities is risky, and can result in financial losses. Trade at your own risk.
