
Python, a dynamic programming language, has rooted itself as an invaluable tool in the data science ecosystem, largely due to its versatile visualization libraries that adeptly transmute data into interpretable visual formats. Libraries such as Matplotlib, Seaborn, Plotly, Bokeh, and Altair not only provide a spectrum of capabilities but also cater to a range of user needs and preferences. Matplotlib is universally recognized for its wide array of 2D plotting functionalities, forming a base upon which Seaborn is built, further simplifying the creation of statistical graphics. Plotly and Bokeh elevate visualization by introducing interactive and real-time streaming plots, greatly enhancing user engagement and data exploration. Altair, a declarative statistical visualization library, distinguishes itself by employing a syntax that is both user-friendly and expressive, ensuring that visualization code is succinct and comprehensible. These varied libraries, collectively, enhance the Python visualization landscape, empowering data analysts, scientists, and developers to weave intricate data stories that facilitate informed decision-making and insights derivation.
Matplotlib
Matplotlib is a comprehensive library for creating static, animated, and interactive visualizations in Python. Developed by John Hunter in 2002, Matplotlib provides a MATLAB-like interface for plotting and is used across various academic and commercial domains. It provides an object-oriented API for embedding plots into applications using general-purpose GUI toolkits, like Tkinter, wxPython, Qt, or GTK.
Here are some general features of Matplotlib:
Easy to get started: Simple syntax and function calls make it accessible for beginners.
Control: It offers fine-grained control over every element in a figure, including figure size and DPI, line width, color and style, axes, axis and grid properties, text and font properties, etc.
Variety of Plots: Matplotlib allows users to create a wide variety of plots and charts, including line plots, scatter plots, bar graphs, error charts, histograms, power spectra, bar charts, and much more.
Export and Embedding: You can export plots to a variety of formats (like PNG, PDF, SVG, and EPS), and embed them in your applications.
Integration: It is used alongside NumPy, SciPy, and other Python science and data libraries.
Let's walk into examples of various types of plots:
Histogram in Matplotlib
A Histogram is a representation of the distribution of numerical data. It is an estimate of the probability distribution of a continuous variable. To construct a histogram, follow these steps:
Bin the range of values: Divide the entire range of values into a series of intervals (bins).
Count values: Count how many values fall into each interval.
The data points are split into bins, and the number of data points in each bin is represented by the height of the bar.
Creating a Histogram Using Matplotlib:
Let’s dig into a practical example:

Explanation:
Sample Data: scores list contains the sample data representing test scores of 100 students.
plt.hist() Function: This function generates the histogram. The first argument is the dataset, and the second argument, bins, determines the edges of the bins. The edgecolor parameter outlines the bars in the histogram.
Titles and Labels: plt.title(), plt.xlabel(), and plt.ylabel() are used to add a title to the plot and labels to the axes, enhancing the interpretability.
Displaying the Plot: plt.show() is used to display the plot.
Adjusting Bins:
Binning can significantly impact your understanding of the data. Too many bins will over-complicate the visualization, while too few bins might oversimplify the data.
Equal-width Binning: Dividing the data into intervals of equal size.
Equal-frequency Binning: Ensuring that each bin has the same number of observations.
In the code example above, bins are manually set to represent scores grouped by tens (60-70, 70-80, etc.). This is an example of equal-width binning.
Boxplot using Matplotlib
A boxplot, also known as a whisker plot, is a graphical representation of the distribution of a dataset. It is a standardized way of visualizing the distribution of data based on a five-number summary: minimum, first quartile (Q1), median (Q2), third quartile (Q3), and maximum.
Components of a Boxplot:
Median (Q2/50th Percentile): the middle value of the dataset.
First Quartile (Q1/25th Percentile): the middle number between the smallest number (not the minimum) and the median of the dataset.
Third Quartile (Q3/75th Percentile): the middle value between the median and the highest value (not the maximum) of the dataset.
Interquartile Range (IQR): the distance between the first and third quartiles, calculated as Q3 - Q1.
Whiskers: These are the lines that extend from the top and bottom of the box. They indicate variability outside the upper and lower quartiles, hence they can be used to identify any outlier in the data.
Outliers: Data points that fall far from the other data points. They're usually represented as dots above or below the whiskers.
Creating a Boxplot using Matplotlib:
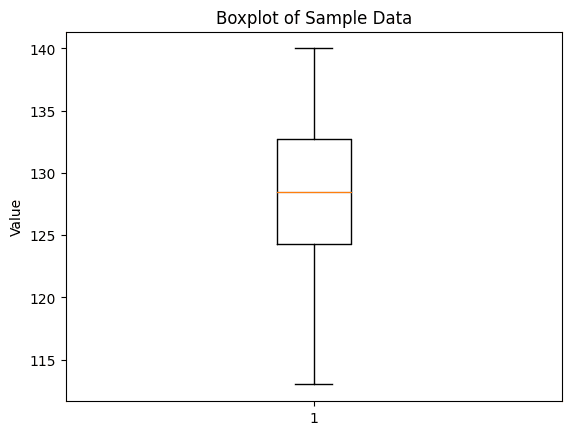
Explanation:
plt.boxplot(data): The boxplot() function from the pyplot module is used to create the box plot. The data is passed as the argument.
plt.title() and plt.ylabel(): These functions are used to set the title of the boxplot and the label for the y-axis respectively.
plt.show(): This function displays the boxplot.
In the generated boxplot, you'll see a box representing the interquartile range (IQR). The line inside the box is the median of the data. The whiskers extend to 1.5 times the IQR. Any data point outside this range is considered an outlier and is represented as individual points outside the whiskers.
Boxplots are powerful as they provide a concise visualization of the distribution of the data, showcasing the central tendency, spread, and shape of the distribution. They also highlight any outliers, making them essential tools in exploratory data analysis.
Line Charts using Matplotlib
A line chart or line graph is a type of chart that displays information as a series of data points called 'markers' connected by straight line segments. It's a basic type of chart common in many fields and is used to represent time-series data or the sequence of values for a particular variable.
Characteristics and Uses of Line Charts:
Time-Series Analysis: One of the most common uses is to track changes over periods of time.
Trend Identification: Helpful in identifying patterns or trends over a duration.
Comparison: Can be used to compare multiple datasets by plotting multiple lines on the same graph.
Creating a Line Chart using Matplotlib:
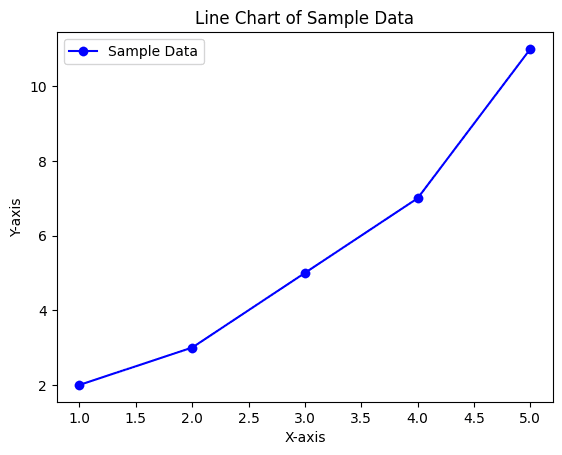
Explanation:
plt.plot(x, y, ...): This function is used to create the line chart. The first two arguments are the X and Y values. Additional arguments help customize the appearance of the line and markers.
label: Represents the label for the line which will be shown in the legend.
color: Sets the color of the line.
marker: Represents the shape of the markers. The 'o' value gives circular markers.
linestyle: Defines the style of the line. The '-' value gives a solid line.
plt.title(), plt.xlabel(), and plt.ylabel(): Used to set the title of the chart and labels for the axes.
plt.legend(): Displays the legend on the chart.
plt.show(): This function displays the chart.
Multiple Lines on One Chart:
You can easily plot multiple lines on one chart by calling the plt.plot() function multiple times before calling plt.show().
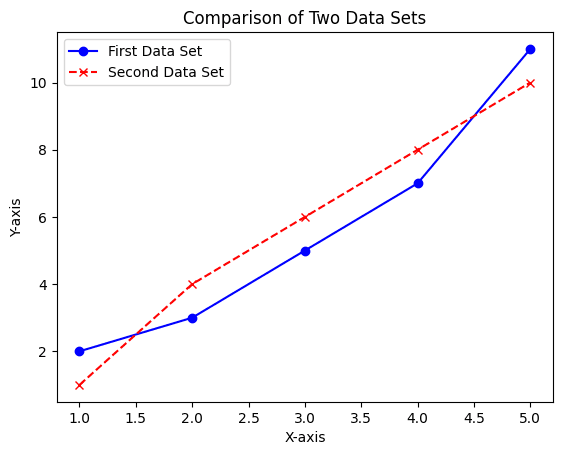
Line charts are fundamental in data visualization, especially for time-series data. They provide a clear picture of data trends and patterns over a specified period. Matplotlib's extensive customization options, from colors and markers to linestyles, make it an invaluable tool for creating detailed and informative line charts.
Scatter Plot using Matplotlib
A scatter plot (or scatter graph) is a type of data visualization that uses dots to represent the values obtained for two different variables - one plotted along the x-axis and the other plotted along the y-axis. Scatter plots are used to observe relationships between variables.
Characteristics and Uses of Scatter Plots:
Relationship Analysis: Scatter plots are instrumental in examining the relationship between two variables. If the dots cluster in a specific way, you might be able to draw conclusions about how those two variables behave.
Correlation Identification: Used to see if one variable increases (or decreases) as the other increases (or decreases). It helps in understanding positive, negative, or no correlation between variables.
Outlier Detection: Any dot that lies far from the general grouping of the rest can be considered an outlier, providing a visual way to identify anomalous data points.
Creating a Scatter Plot using Matplotlib:
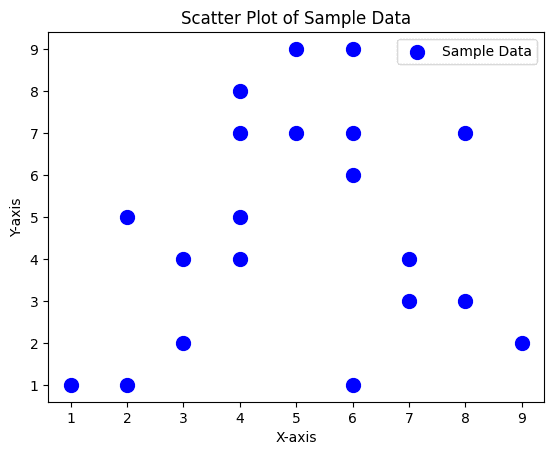
Explanation:
plt.scatter(x, y, ...): This function is used to create the scatter plot. The first two arguments are the X and Y values. Additional arguments help customize the appearance of the points.
label: Represents the label for the scatter plot which will be shown in the legend.
color: Sets the color of the points.
marker: Represents the shape of the markers. The 'o' value gives circular markers.
s: Defines the size of the markers.
plt.title(), plt.xlabel(), and plt.ylabel(): Used to set the title of the chart and labels for the axes.
plt.legend(): Displays the legend on the chart.
plt.show(): This function displays the chart.
Bar Charts using Matplotlib
A bar chart or bar graph is a chart or graph that presents categorical data with rectangular bars with heights (or lengths) proportional to the values that they represent. Bar charts can be oriented either vertically (column chart) or horizontally.
Characteristics and Uses of Bar Charts:
Categorical Data Visualization: Bar charts are used when you want to compare a single category of data between individual sub-items.
Data Comparison: They are excellent for comparing data across categories.
Frequency Distribution: Bar charts can also be useful for seeing the frequency distribution of categorical data.
Creating a Vertical Bar Chart using Matplotlib:
Explanation:
plt.bar(...): The primary function to plot vertical bar charts. The first argument represents the categories, and the second argument represents their respective values.
color: An optional argument that sets the color of the bars. Here, different colors are specified for each bar.
plt.title(), plt.xlabel(), and plt.ylabel(): Used to set the title of the chart and labels for the axes.
plt.show(): This function displays the chart.
Creating a Horizontal Bar Chart:
Horizontal bar charts are suitable when category labels are long or when you have more than a few items to compare. Here's how you can create one:
Pie Chart using Matplotlib
A pie chart is a circular statistical graphic, which is divided into slices to illustrate numerical proportions. In a pie chart, the arc length of each slice is proportional to the quantity it represents.
Characteristics and Uses of Pie Charts:
Proportional Representation: Pie charts are used to depict proportions and percentages. Each slice of the pie represents a proportion of the whole.
Categorical Data Visualization: Suitable for data which can be categorized and represented as a fraction of the whole.
Limited Categories: Best used when there are fewer categories, as too many slices can make the chart hard to interpret.
Creating a Pie Chart using Matplotlib:

Explanation:
plt.pie(...): The primary function to plot pie charts.
sizes: List of values for each category.
explode: Specifies the fraction of the radius with which to offset each wedge. Used to highlight specific sections.
labels: List of labels for each category.
colors: List of colors for each category.
autopct: String format to label the wedges with their numeric value. This helps in directly viewing percentages on the chart.
shadow: Draws a shadow beneath the pie.
startangle: Rotates the start of the pie chart by the specified degrees.
plt.axis('equal'): Ensures the pie chart is drawn as a circle, maintaining the aspect ratio.
plt.title(): Sets the title of the chart.
plt.show(): Displays the chart.
While pie charts can be visually appealing and provide an intuitive sense of proportions at a glance, they also have their drawbacks:
Comparisons: It can be hard to compare sizes of slices, especially if they're close in size.
Over-cluttering: If there are many categories, the pie chart can become cluttered and hard to interpret.
Overuse of 3D and explode effects: These can make the chart harder to read and might distort the data representation.
Case Study: Banking Customer Insights Visualization
Background:
The banking industry is increasingly relying on data analytics to drive business strategies and decisions. This case focuses on XYZ Bank, a medium-sized bank that offers a variety of financial services to its customers. With increasing competition in the banking sector, XYZ Bank wants to leverage its data to understand customer behavior better and to identify potential areas for growth and improvement.
Objective:
XYZ Bank aims to understand the following:
The distribution of account balances across its customer base: This will help them identify high net-worth individuals and those who might need financial advice or new account options.
The dispersion and nature of loan amounts among its customers: It will help in understanding loan preferences and any potential red flags regarding loan sizes.
The popularity of the type of accounts (Savings vs. Checking): Useful for tailoring marketing campaigns or new account features.
The relationship between account balances and loan amounts: To identify if individuals with higher balances tend to borrow more or less.
The loan status distribution: Helps in understanding how many customers are active loan customers, how many have closed their loans, and how many do not have any loans. This could be a crucial metric for the loan department to target specific segments.
Data:
The bank has a dataset containing the following information for about 1000 customers:
Customer ID: A unique identifier for each customer.
Name: Name of the customer.
Account Balance: The current balance of the customer in the bank.
Account Type: The type of primary account - Savings or Checking.
Loan Amount: The amount of loan (if any) the customer has borrowed from the bank.
Loan Status: Indicates whether a customer's loan is active, closed, or if the customer has no loan.
Methodology:
To gain the required insights, the bank will employ various data visualization techniques. Each visualization will target a specific insight from the objective:
Histogram: To understand the distribution of account balances.
Boxplot: To analyze the spread and outliers in loan amounts.
Line Chart: To visualize the trend in account balances (if there's any discernible trend).
Scatter Plot: To find the relationship between account balances and loan amounts.
Pie Chart: To know the distribution of account types.
Bar Chart: To visualize the distribution of loan statuses.
Expected Outcomes:
By the end of this study, XYZ Bank hopes to:
Understand its customers better in terms of their financial behavior.
Identify potential areas for new services or improvements in existing services.
Drive strategic decisions based on concrete data-driven insights.
Enhance customer engagement by tailoring offerings based on the insights derived.
Challenges:
Data accuracy and completeness: For any data-driven analysis, the accuracy and completeness of the dataset are crucial.
Interpretation of results: While visualizations can provide insights, the correct interpretation of these insights is essential to drive accurate strategies.
External factors: Many external factors can influence banking behavior, like economic conditions, which might not be captured in the dataset.
After this case study analysis, the bank will be better positioned to decide its next steps in terms of marketing strategies, service improvements, and customer engagement activities.
Let's tackle the visualizations step by step, breaking down the code and interpreting the results for each visualization from our case study.
Loading the Data

Column Interpretation:
Customer ID:
This represents a unique identifier for each customer. It helps in differentiating each customer in the dataset and ensuring that data for each individual can be tracked without confusion.
Name:
This column contains names (or potentially pseudonyms/codenames) of the bank's customers. The purpose is likely to recognize individual customers, though for privacy concerns in this dataset, real names might have been replaced with alphanumeric strings.
Account Balance:
Represents the current amount of money a customer has in their bank account. This provides insight into the financial health and wealth status of each customer.
Account Type:
Indicates the type of account that the customer holds with the bank. Common types include Savings (typically used for depositing money and earning interest) and Checking (generally used for daily transactions).
Loan Amount:
Shows the amount of money borrowed by the customer as a loan from the bank. A value of 0 suggests the customer hasn't taken any loan, while other values indicate the amount borrowed.
Loan Status:
Describes the current status of the loan the customer might have taken. Possible statuses include:
No Loan: Indicates the customer hasn't borrowed any loan.
Closed: Indicates the customer had a loan in the past but has now repaid it.
Active: Indicates the customer currently has an ongoing loan with the bank.
These columns collectively provide a comprehensive view of the customer's financial relationship with the bank, covering both deposit and credit aspects.
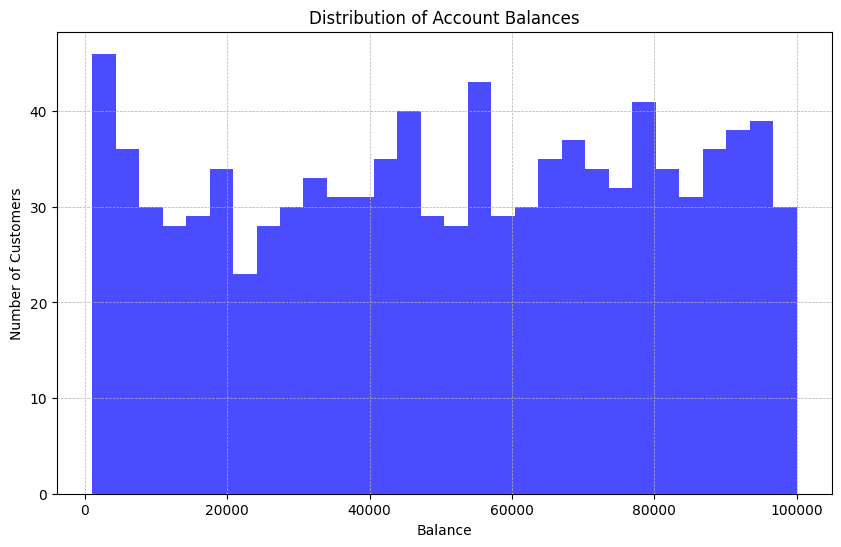
"Distribution of Account Balances" Histogram:
Low-Balance Customers: There's a significant number of customers with balances near 0, suggesting a segment of customers who maintain minimal balances.
Mid-Range Gaps: Fewer customers have balances between 20000 and 40000, indicating a gap in mid-range account holders.
Popular Balance Brackets: Peaks at around 40000, 60000, and close to 100000 suggest there are specific balance brackets that are more common among the bank's customers.
High Balance Variation: The distribution for high balances (above 80000) is uneven, hinting at variability in the higher balance range.

Dispersion of Loan Amounts:
This is a box plot showcasing the distribution of loan amounts.
The median loan amount (represented by the orange line) is around 25,000.
The majority (approximately 50%) of loan amounts (represented by the interquartile range or the box) lie between roughly 15,000 and 35,000.
The "whiskers" (lines extending from the box) suggest that there are loan amounts as low as almost 0 and as high as around 45,000 that are not considered outliers.
Loan amounts beyond these whiskers can be considered outliers or extreme values, indicating that very few loans are above 45,000.
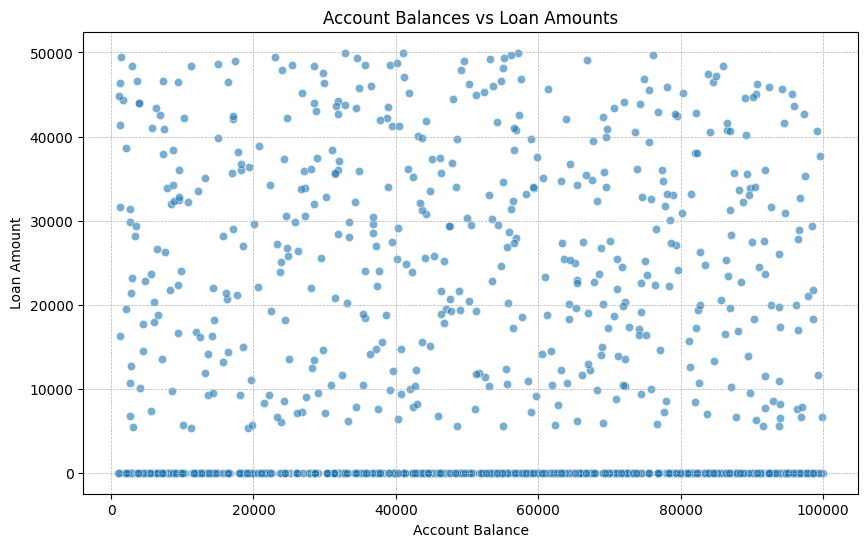
Account Balances vs Loan Amounts:
This scatter plot visualizes the relationship between account balances and loan amounts.
There's a dense clustering of points around 0 loan amount across various account balances, indicating that many customers with varying account balances haven't taken significant loans.
The dispersion of points in the middle of the plot suggests a weak correlation between the account balance and the loan amount. This means a customer with a high account balance might have a low loan amount and vice versa.
There are few instances where customers with high balances (near 100,000) have taken significant loans (near 50,000).

Distribution of Account Types:
This pie chart represents the proportion of savings vs. checking accounts.
The almost equal distribution indicates a balanced portfolio of account types for the bank.
With 50.2% savings accounts and 49.8% checking accounts, the bank doesn't show a pronounced bias towards either type, suggesting a diversified customer base in terms of account preferences.

Loan Status Overview:
No Loan: The largest group consists of customers who have never availed a loan. This segment has approximately 500 individuals, reflecting a significant portion of the customer base that might be potential candidates for loan products in the future.
Closed: The second-largest group, with around 250 customers, have had loans in the past which they have successfully closed. This could indicate a segment with a good track record of loan repayment.
Active: A slightly lesser number, slightly below 250 customers, have active loans. Monitoring this group is essential to ensure timely repayments and understand loan performance.
Summary
The data visualizations present a comprehensive overview of the loan portfolio of a financial institution. Beginning with account balances, we observe that a considerable number of customers tend to maintain minimal balances close to zero. However, there's a noticeable gap in the mid-range account holders, particularly between 20,000 and 40,000. Despite this, there are specific balance brackets, notably around 40,000, 60,000, and just under 100,000, that seem popular among customers. Interestingly, the distribution for customers with higher balances, particularly those over 80,000, appears uneven, suggesting a diverse range of financial capabilities within this segment. When exploring the dispersion of loan amounts, the median amount sits at approximately 25,000. Most of the loans, encapsulating around 50% of all loans, range between 15,000 and 35,000. However, there are rare instances where loans exceed 45,000, placing them as outliers in the dataset. Most strikingly, the loan status data reveals that a substantial portion, nearing 500 individuals, have not availed any loans at all. This might indicate either a newer customer base or a more savings-oriented clientele. Those with closed loans number around 250, showcasing a good repayment history, while almost a similar number currently hold active loans, pointing towards ongoing financial engagements.
To access and run the Python code yourself, visit the Pyfi GitHub
Written by Numan Yaqoob, PHD candidate